This is a guest blog post by Krzysztof Wosiński who is a quality and cybersecurity engineer of military IT products by day / OSINT researcher and social engineering enthusiast by night. Author of the OSINT hints series on Sekurak (in Polish).
I bet most of you (if not everyone) performed a reverse image search using one of the popular search engines. You upload a file or take a photo and in the blink of an eye you get the results of similar images, a list of websites which contain them, suggestions of related topics, etc. But as usually with these kinds of services, some of them do better than others, some have more options for further search while the others have less.
This little experiment of mine was performed for three most well-known search engines with the “reverse image search” capabilities: Google, Bing and Yandex. Some of you may find the results quite surprising. First things first, however.
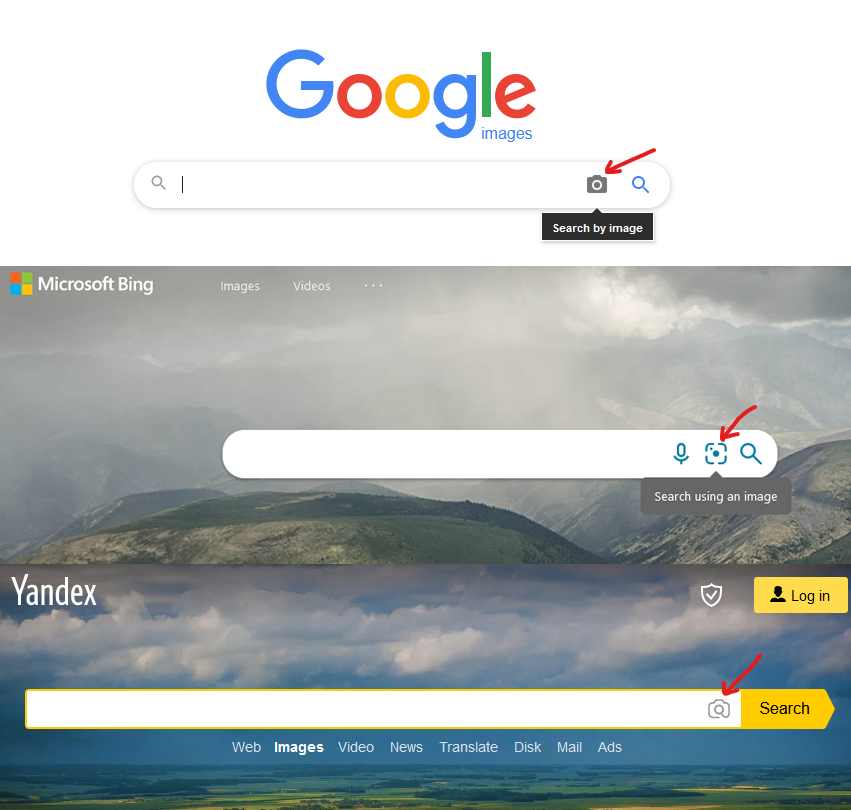
The reverse image search option can be very helpful in all kinds of investigations. Uploading a picture (by selecting a file from your computer or just dragging and dropping the image in the search field) or pasting a link from which the service will download the image provides us with a quick clue on where in the world the photo was taken, what object it depicts or who is the person in the picture. It is worth considering that the three aforementioned services differ in mode of their operation which is evident if we compare the results from searching the same samples. In some cases these search engines have problems with downloading an image from a provided link, which seems to work in our local browser – what helps in that kind of situation is to download the picture and then upload it from our computer. Since my recent OSINT activities had a lot to do with geolocation, I decided to first check how Google, Bing and Yandex cope with photos from around the world.
1. Places
My first shot was a picture taken in Paris, never uploaded to the Internet, showing the Statue of Liberty. This is how the search engines responded:
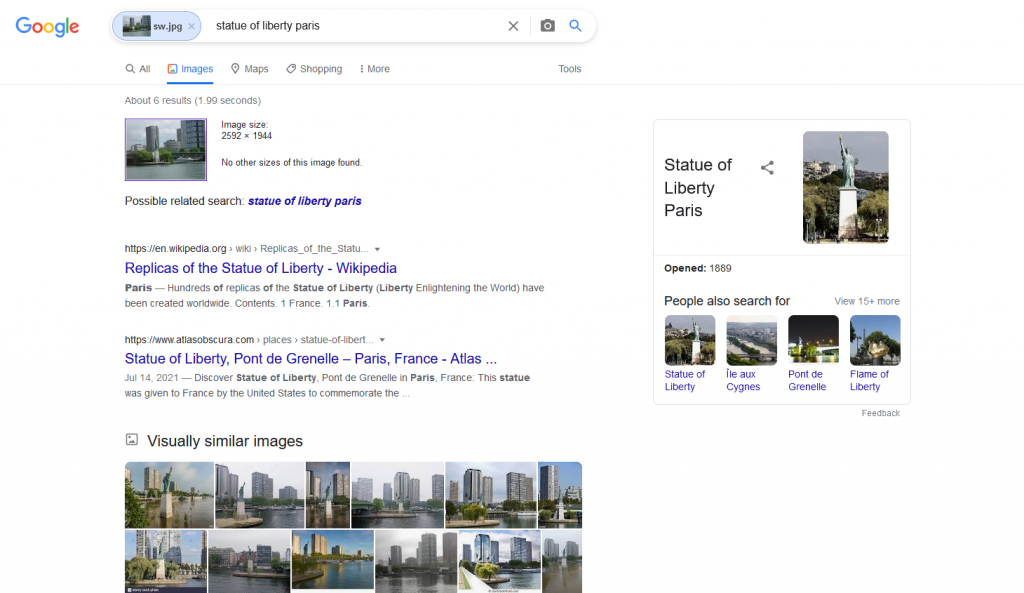
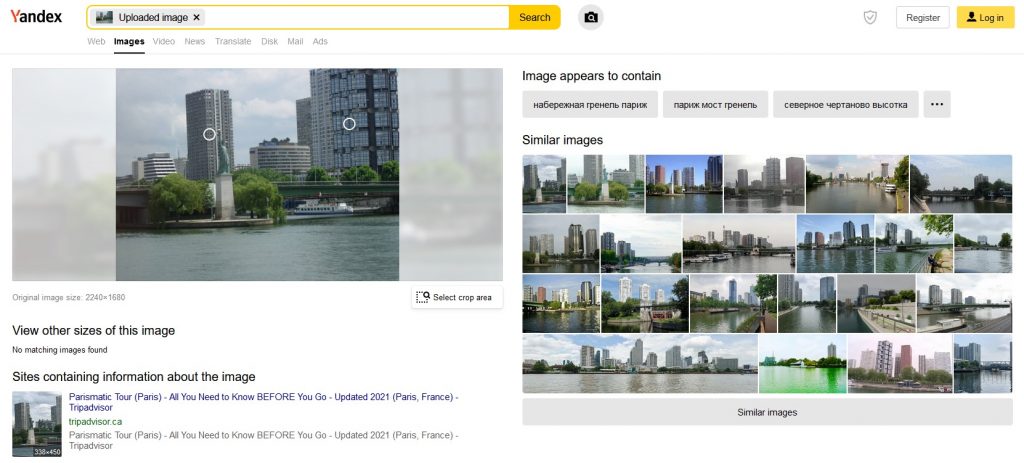
Both Bing and Yandex tell us what place and what object is in the picture. Bing proved to be the weakest one, showing us only two pictures of the same location in Paris, while the rest of the results showed photos from all around the world, from New York to Yokohama. Yandex did identify buildings in the photo (labeling each one as “building” in Russian), which can be further inspected after clicking on them.
So, let’s narrow down our search, by cropping the image to the very part which we are interested in and see the outcome. In this operation Google did the poorest, as it does not provide any option to quickly crop the image. After uploading a picture to the search engine we may only filter images visually similar to ours or filter the image sizes in the results, if found – both options are available under the search field. Therefore, in this case we have to prepare a cropped image of the Statue of Liberty locally. Unfortunately, despite of all our effort, the engine does even worse than before:
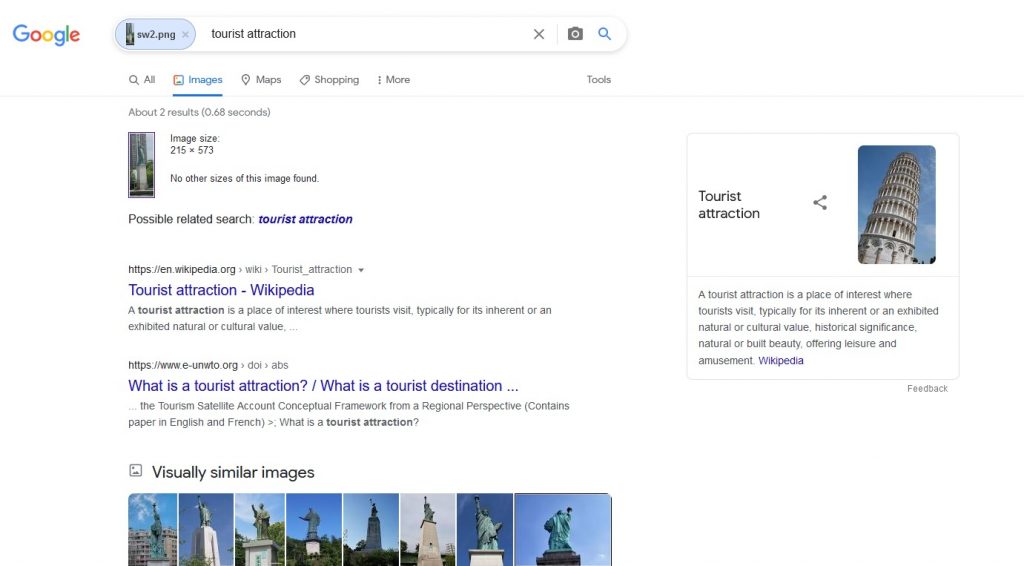
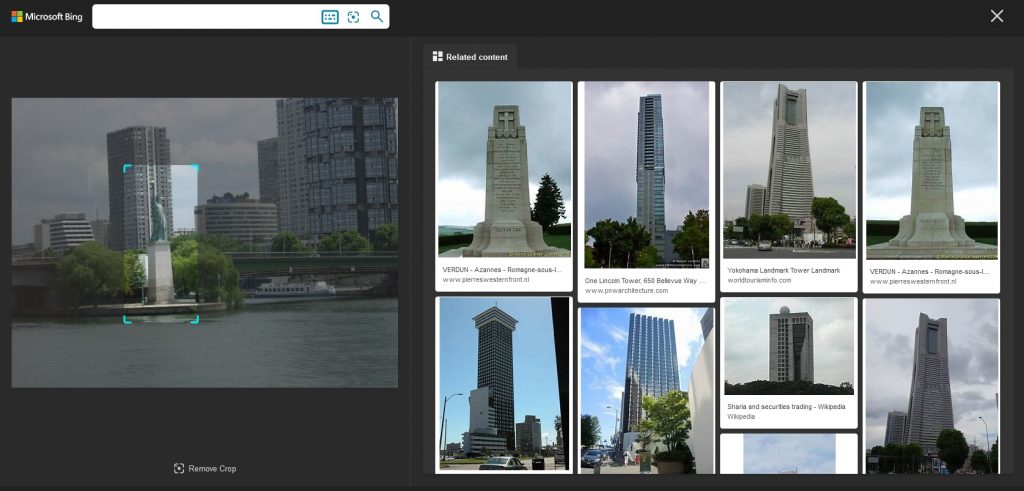
Bing offers us a possibility to select only a part of the previously uploaded image, which it will then use for further searching – this can be done by clicking “Visual Search” under our image.
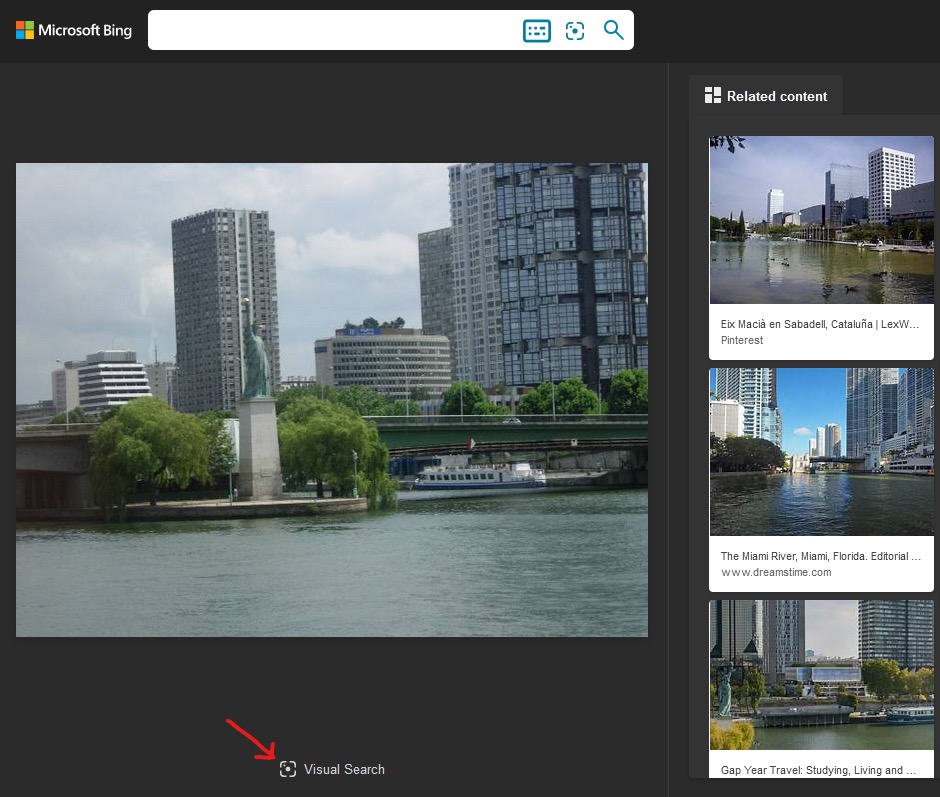
The bad news is that the more we narrow the selected area, the less accurate the results are.
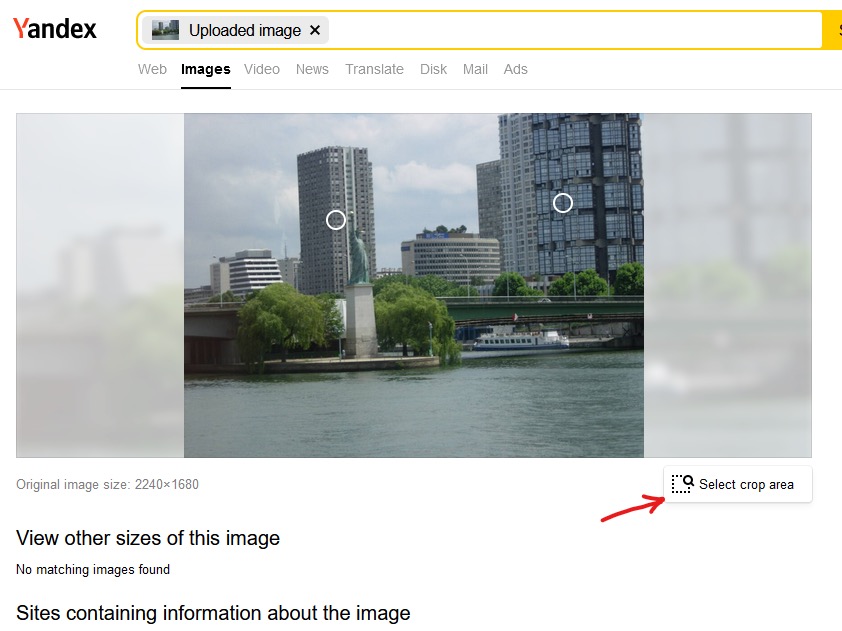
Yandex, just as Bing, gives us an option to quickly narrow down the area in the image used in the search – you just have to click “Select crop area” under the displayed image and select the desired fragment.
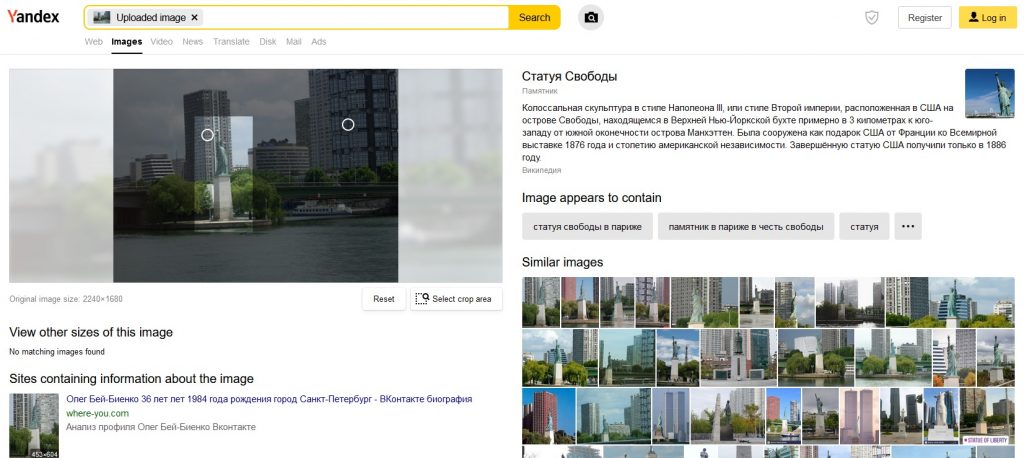
Also this time the engine did well, pointing the sought statue and information on it, although it pointed to the American one, not the one in Paris.
Nevertheless, in this round both Yandex and Google proved to be user friendly and they presented the most accurate data. Bing did a little worse.
2. Text recognition
In my humble opinion, text recognition in the uploaded pictures is one of the best features currently available in the search engines. Of course not all of them do just as well as the others. Let’s start with Google and a photo of an information board in Thailand.
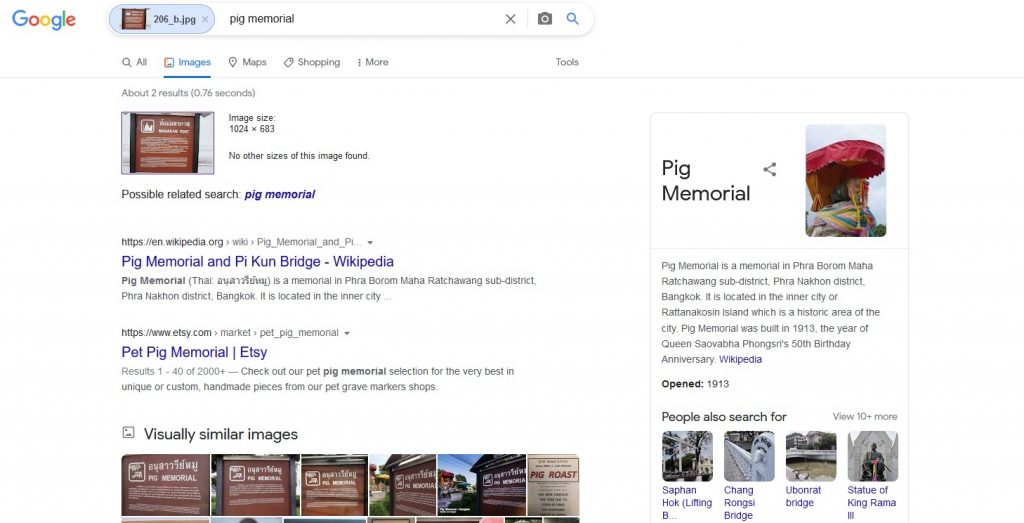
Again, it wasn’t a good result for Google. It was pointing Thailand correctly, but two blocks away from the original location (which was by the way described by the sign in detail both in Thai and in English). This may result from the fact that there is a similar sign in the location which Google found.
Let’s see how Bing handled the same problem:
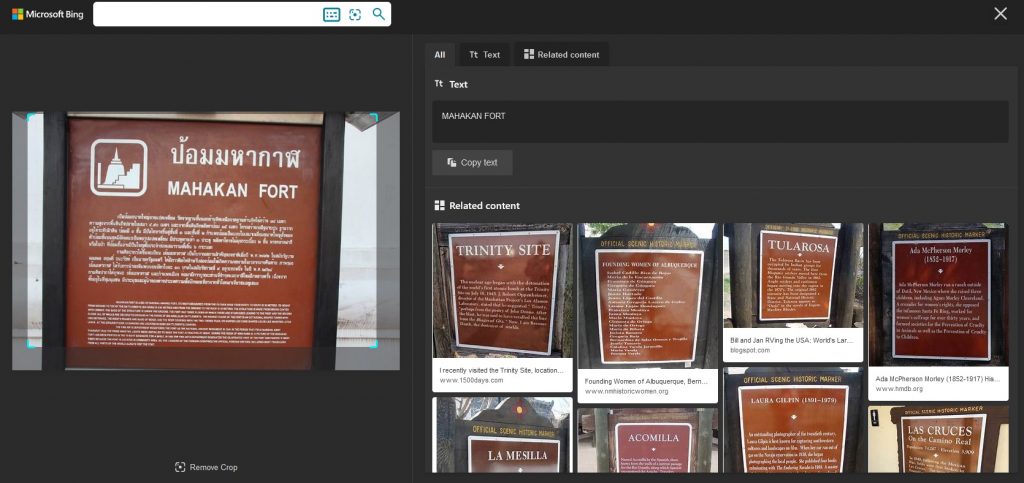
Just as before, what we get in the results are similar boards from the neighborhood. Bing does not offer any additional information which could be connected to the elements in the photo, but we can copy the text recognized from the picture. However, as we can see, the only supported alphabet is the Latin one – the engine even tries to identify Thai characters as Latin ones.
It is therefore time for the third contestant – Yandex:
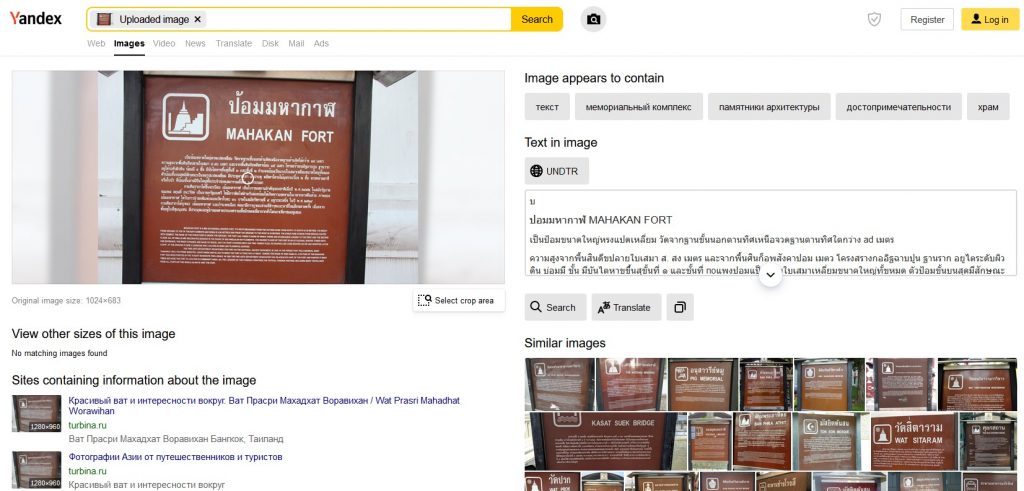
The results show a really big advantage of the tool – text recognition from the image not only for the Latin characters. It may not always work perfectly since it depends on the size and quality of the image, but it is a big step forward – it makes it possible to translate the text that would be difficult to transcribe by just looking at the picture. The recognized text can be translated immediately by clicking the (surprise!) “Translate” button under the text. Besides that, we can also see the results of the similar signs from the surrounding area.
In this category the winner is Yandex due to its aforementioned feature, the second one is Bing, and the last is Google.
3. Cars
As for the next examined object, I decided to use a photo of a classic car. First goes Google:
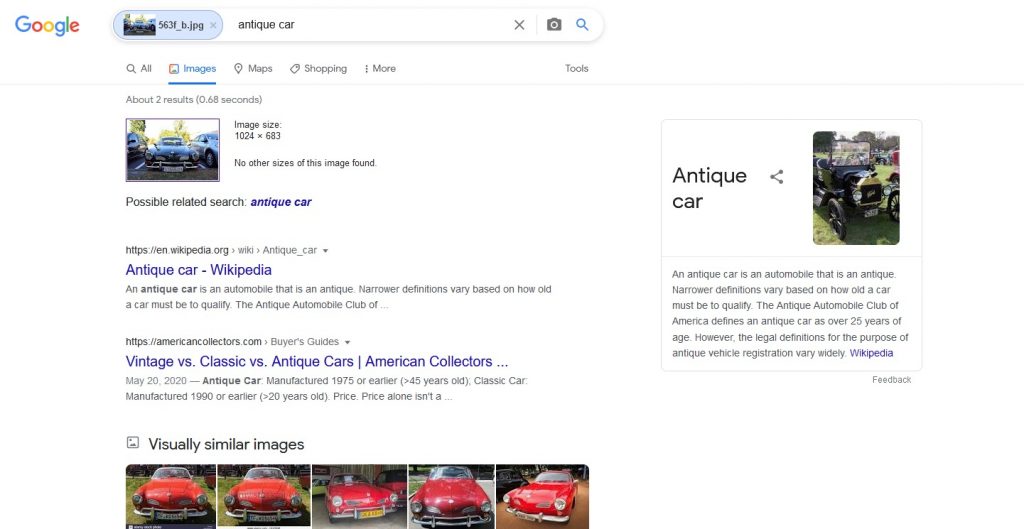
What is worth mentioning is that Google assigns the keywords to the image which it finds most relevant, and puts them in the search field. By changing them we can modify the search results. This time we were able to find out that the vehicle is an antique car and that’s all. However, in this very case among numerous visually similar images there are many depicting the same model as ours, so by clicking them we can jump to the info on the particular model.
Bing did not do well at all this time:
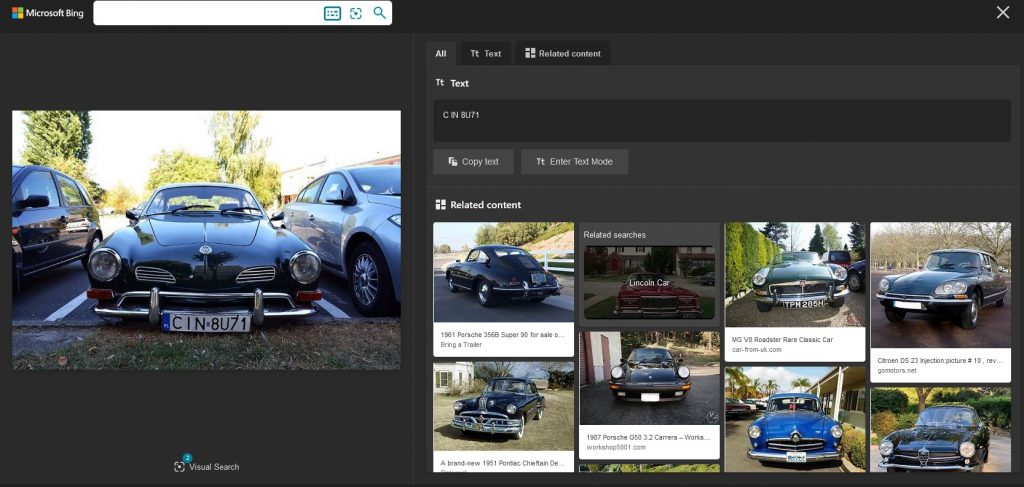
Among the first tens of results there is not even a single one showing our make and model. Some of them are also German cars indeed, but the result remains disappointing anyway and rather seems to be a coincidence.
Yandex showed once again that it’s a pro in terms of searching images:
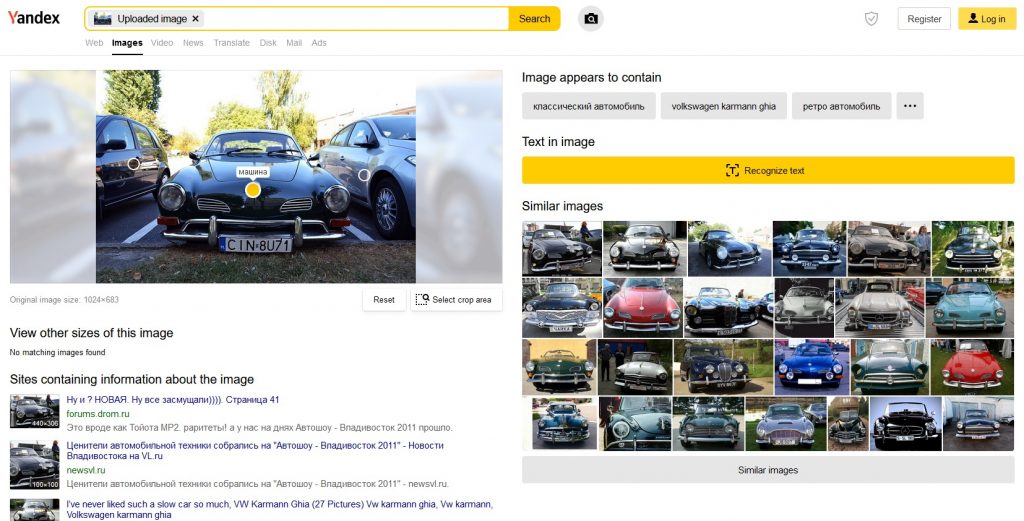
There are representatives of the same make and model as in the source image, and additionally we have sites containing this image (to be honest, these sites don’t really have this particular image, only a very similar one), as well as textual links above similar images, telling us exactly what model is that (although they are written in Cyrillic). If you decide to use Yandex more often, you may find it easier to use the automatic page translation option in Chrome.
4. Fruit
The fourth type of objects used in this experiment are fruits (pomegranates to be exact), but in a form which is not so easy to analyze – in larger amounts and sliced. Let’s start with Google:
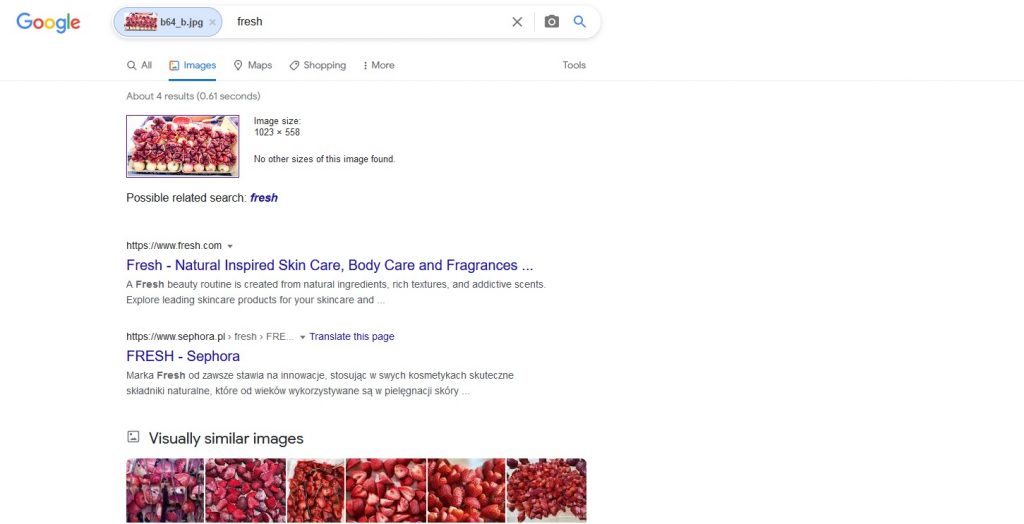
Unfortunately, the keyword assigned in this case is „fresh”, and the similar images show… strawberries! Well, we can only add that the sites listed below indeed contain similar images and indicate that these are pomegranates.
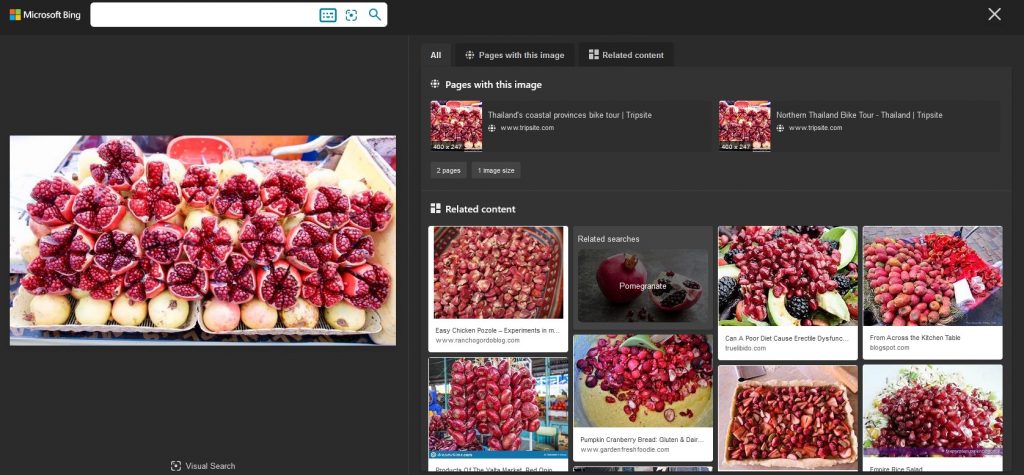
Bing did better – the listed sites contain the picture of the fruit and the similar images lead us in the right direction.
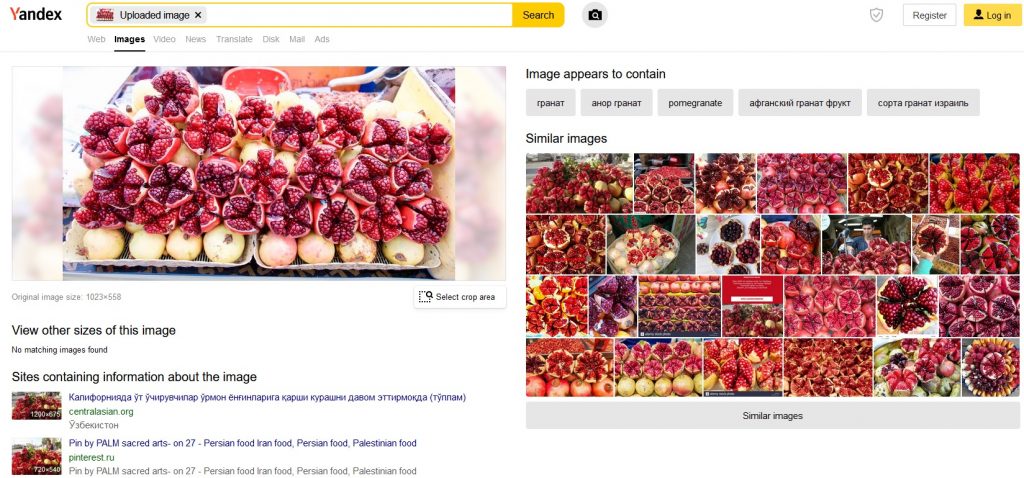
Yandex also managed to search it without any problems. Similarly to Bing, it shows the sites containing information found on the searched image, textual information which is in line with reality, and similar images – not showing any strawberries.
5. Logos
In order to find out how the search engines manage to handle a logo sign, I took a photo of a sign of one of Japanese delivery companies. It is taken from a little angle and it is not so clear. I also took the same sign in an “original” version from the company’s website for comparison. While all three search engines did a good job for the original logo, the photo did not give such good results. But this time Google did it:
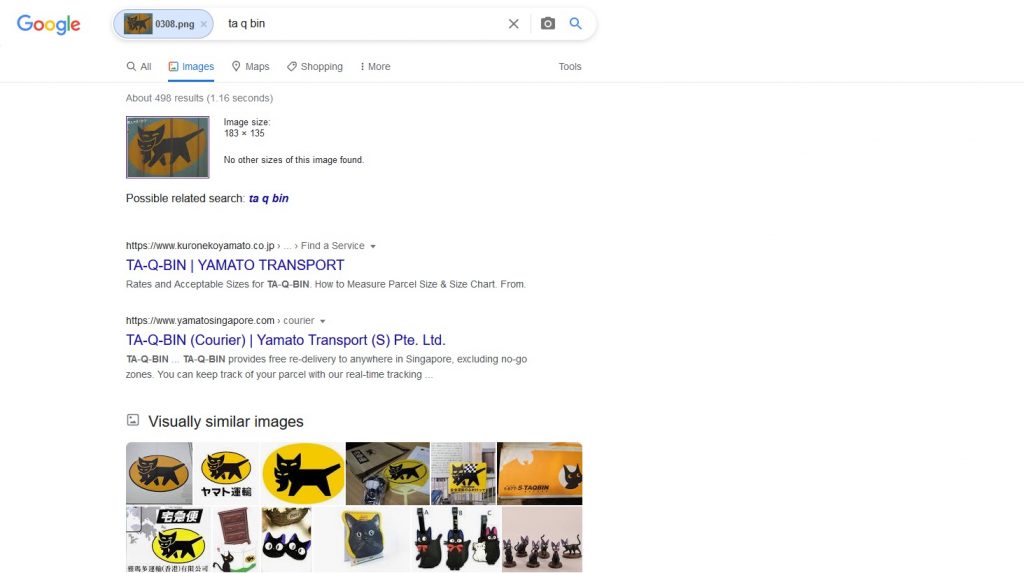
The resulting pages correspond to the company using that logo. Also the similar images offer us an opportunity to identify the company this sign belongs to.
This time Bing didn’t make it:
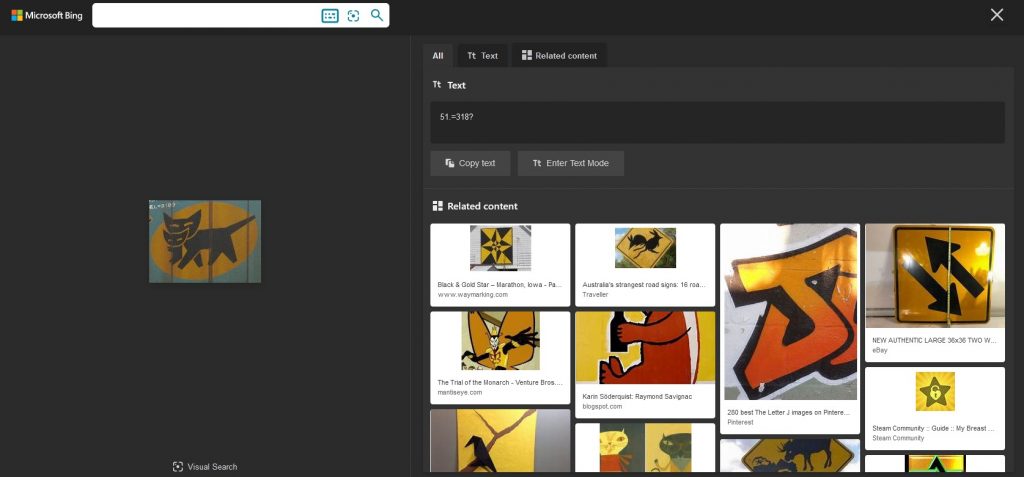
Similar images aren’t even similar, and the recognized text tells us nothing. Maybe Yandex then?
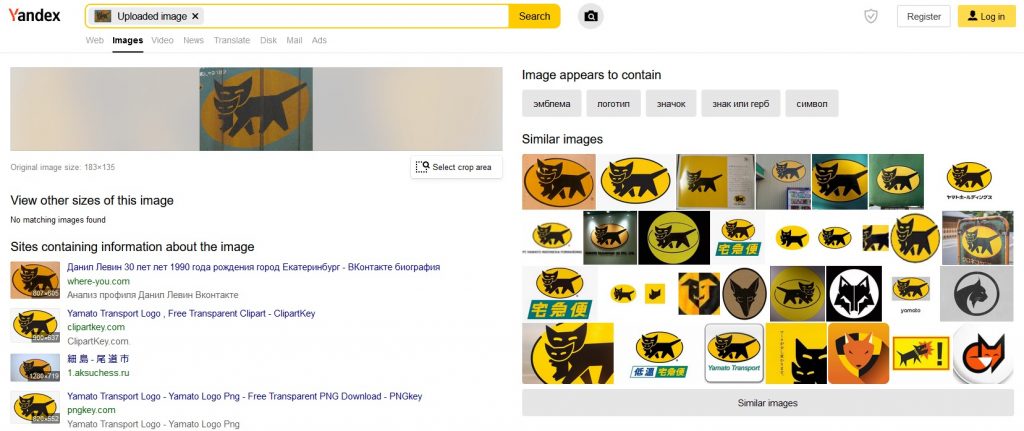
Yes, much better. There are really similar images, pages containing the sign, and we can proceed further.
I also performed a similar test using the Beijing Olympics logo from 2008, with a similar set of results. However, in yet another trial, using a logo of a well-known Polish bakery, none of the search engines succeeded in identifying the actual brand.
6. Faces
Last but not the least important criteria of our little experiment is face recognition. Amid the objects of the investigation were: photos of Swiss ski jumpers (which were never uploaded to the Internet earlier, and showing them wearing usual clothes, not ski uniforms), a cropped and modified photo of one of the well known antivirus software creators, as well as a stock photo of a girl. Due to the fact that I don’t remember asking the ski jumpers for a consent to use their image online, I darkened some parts of the screen caps, but the result will show that it is really them.
First attempt – Google vs. ski jumpers:
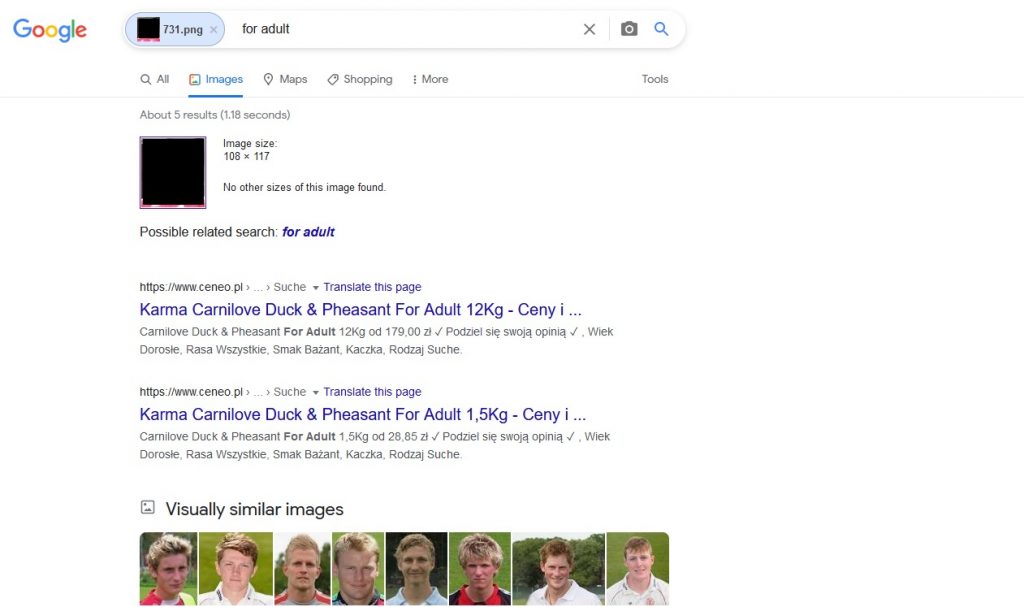
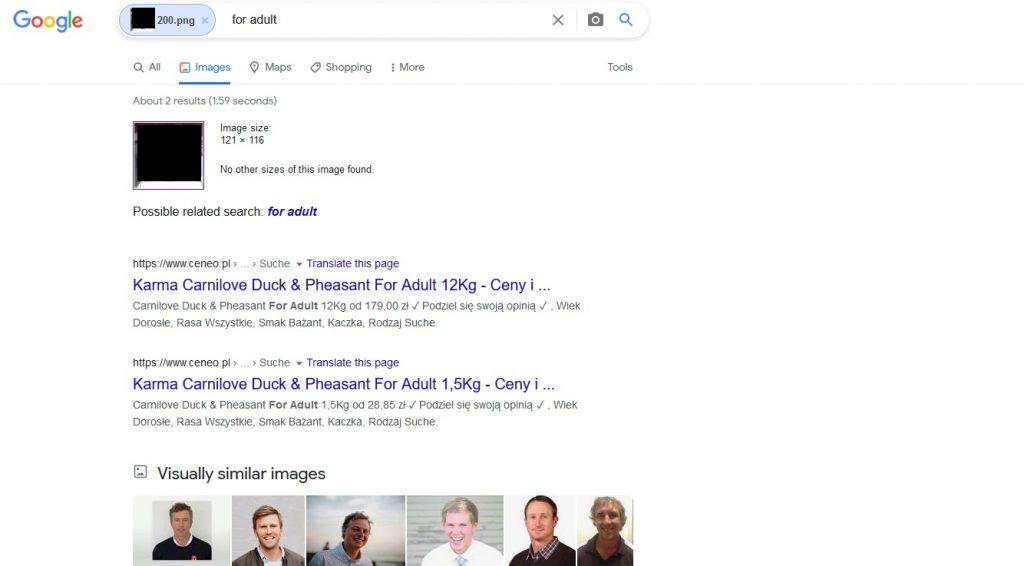
Again, this time we didn’t manage to get any valuable information on who is in the photo. The only information “for men” from the keywords gives us a clue that both were classified as men by the search engine, but the similar images are only similar regarding the color distribution.
Let’s not give up and try the same with Bing:
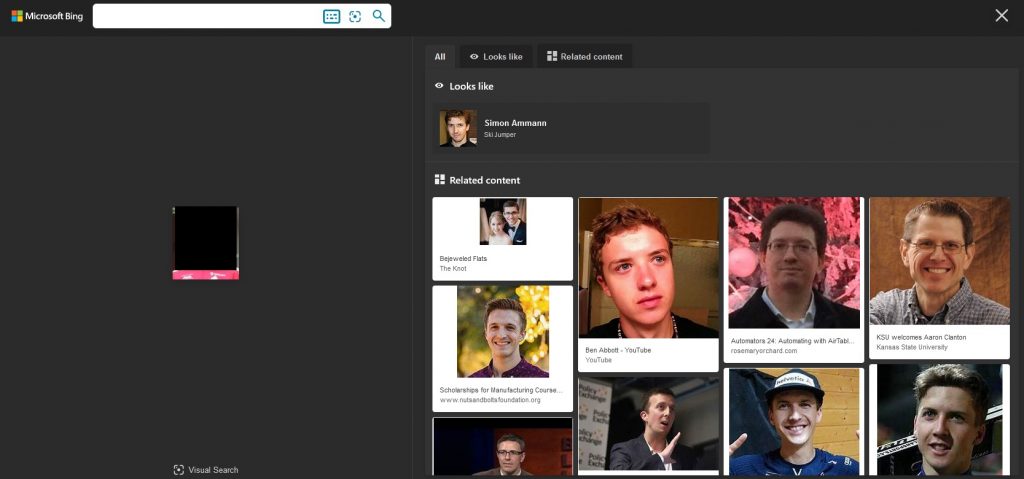
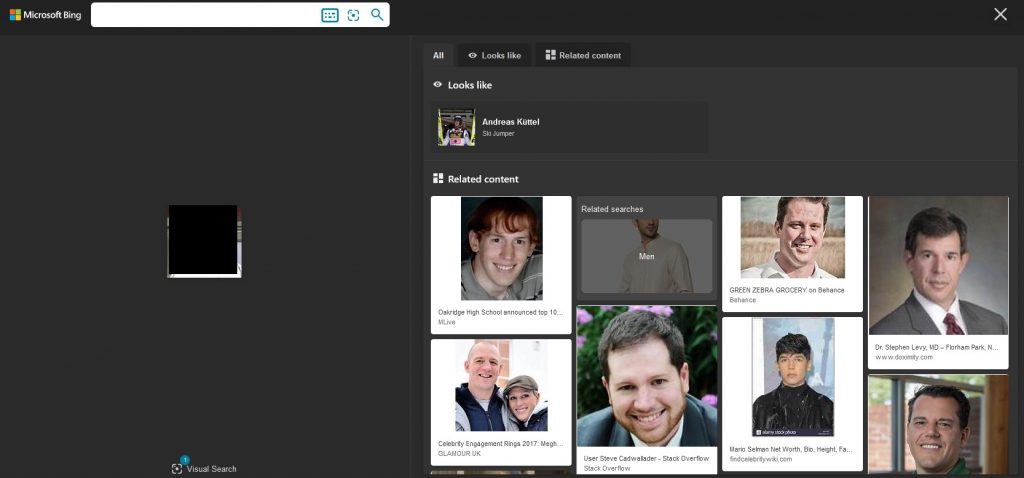
Bingo! Both were identified correctly from small, low quality pictures. Similar images were not similar at all, but at least we know whom to look for.
Will Yandex perform as well as it did previously?
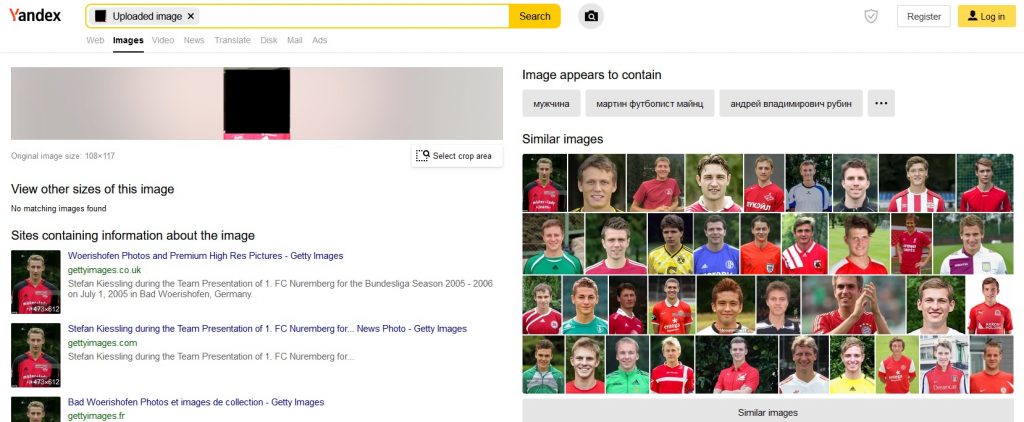
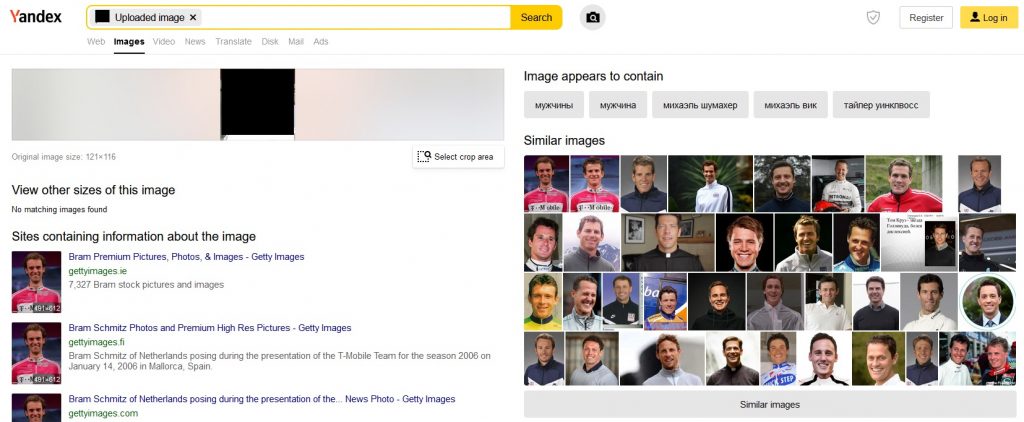
Not this time – they were only identified as men, just as in the case of Google.
For comparison, I also tried to search with these images throughPimEyes, which is a facial recognition search tool, but it didn’t even analyze them, saying that there are no faces in the pictures.
The results for the modified (desaturated, tilted and with increased contrast) picture of John McAfee gave the same result in Google – a keyword saying “for men”. By turning the picture upside down (by the way, did you know that if you see a an upside down photo of a person which you know, your brain will not be able to identify the person as quickly and well as it can by looking at a picture which is in the right position?), the results indicate “hair loss” and no connection to the person which we look for. Bing did well both for the modified and the rotated photo, although in the second case the identification is only performed correctly in the similar photos section, not in the results. Yandex identified the person in both cases by finding the source pictures and pointing to sites containing them, which led us to the man in the picture. PimEyes only managed to handle the desaturated photo, the rotated one wasn’t identified as a face.
In the case of a photo of a girl, it is only worth mentioning that Google didn’t surprise us and showed only somewhat similar images of women, categorized as “beautiful blonde with green eyes”, while Bing and Yandex gave a list of social media sites and forums containing avatars with the image of that girl.
Summary
As for Google, which seems to be the most recognizable search engine, the outcome of the experiment was disappointing. It wasn’t a leader in any of the categories. Bing had only one real win, in the facial recognition case, but the other results were only sometimes satisfying. Yandex showed that reverse image search is its thing, and the text recognition function dealing with non-Latin alphabets really deserves attention.
Let us quickly sum up the results:
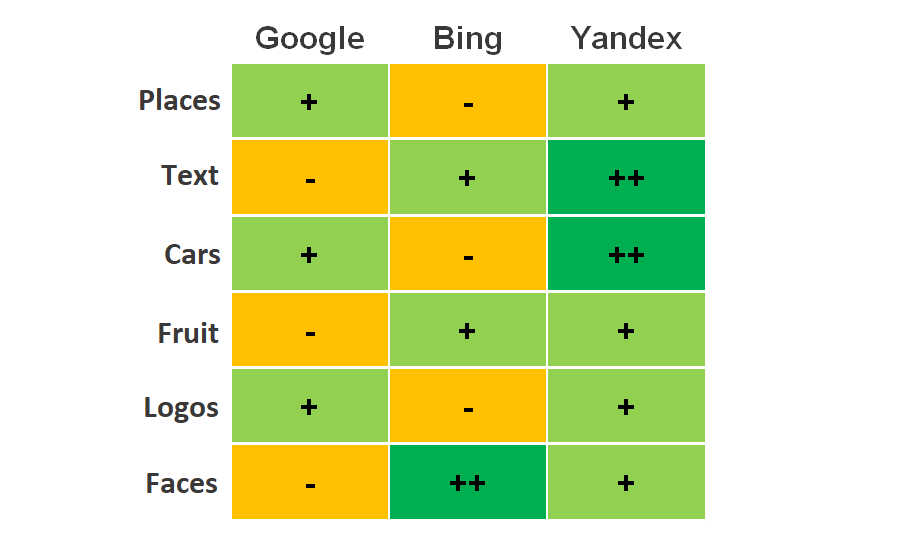
We can say that in most cases Yandex was the best tool to use, but in some scenarios Bing seemed to be good as well. For some the generally weak results of Google searches may be a surprise, but it is worth remembering that just as for the text searches, the results of the reverse image search also should be compared between different search engines.
By all means, this was not a real scientific experiment – the purpose of this comparison was only to test and demonstrate the differences between search engines, basing on a limited set of samples. While doing it I also used other samples, but the ones mentioned in this article are the ones which show the differences best. I encourage you to test these sites in your OSINT investigations, as well as others available on the Internet.
If you want to read more about OSINT (in Polish), please visit my OSINT hints series on Sekurak.
— Krzysztof Wosinski (@SEINT_pl)