Note: there is also a live stream where I talk about the same topic: https://www.youtube.com/watch?v=QBkLI35sxVs&feature=youtu.be
Within last year I shared a a few writeups of my bypasses of HTML sanitizers, including:
- Write-up of DOMPurify 2.0.0 bypass using mutation XSS
- Mutation XSS via namespace confusion – DOMPurify < 2.0.17 bypass
While breaking sanitizers is fun and I thoroughly enjoy doing it, I reached a point where I began to think whether I can contribute even more and propose a fix that will kill an entire class of bypasses.
This is what I did and in this blog post I’m sharing what exactly was changed and why.
This is the first part of the series; in the second one I’ll explain differences between document parsing and fragment and how it can be abused to bypass sanitizers.
Basics of HTML parsing
First things first, in this blogpost I’ll focus on DOMPurify, a really popular library that is an HTML sanitizer. So its job is to take an untrusted snippet of HTML and delete all attributes and elements that can be exploited to perform Cross-Site Scripting. DOMPurify set the bar higher than almost all other sanitizers because the default configuration allows not only HTML markup, but also SVG and MathML (known collectively as “foreign content”). And foreign content is the usual root cause of the security issues.
So let’s start with some basics of HTML parsing and serialization. Parsing is how HTML text is “changed” into a DOM tree. Serialization is the opposite way – changing DOM tree into a text.
So if we have a simple markup like:
|
1 |
<div id=x>Hello!</div> |
The result of parsing is the following document:

While the serialization would the div would return:
|
1 |
<div id="x">Hello!</div> |
Note that the serialization is not equal (but equivalent) of the original markup. Value of attribute id was not originally in the double-quotes but it is after serialization.
Now we may not be thinking about it on daily basis but every element in the DOM tree also has a namespace. By default all elements have HTML namespace but it is possible to switch namespace to either SVG or MathML. This is done via <svg> and <math> respectively.
So let’s try with the following markup:
|
1 2 3 |
<div>Hello!</div> <svg>Hello!</svg> <math>Hello!</math> |
It is parsed into:
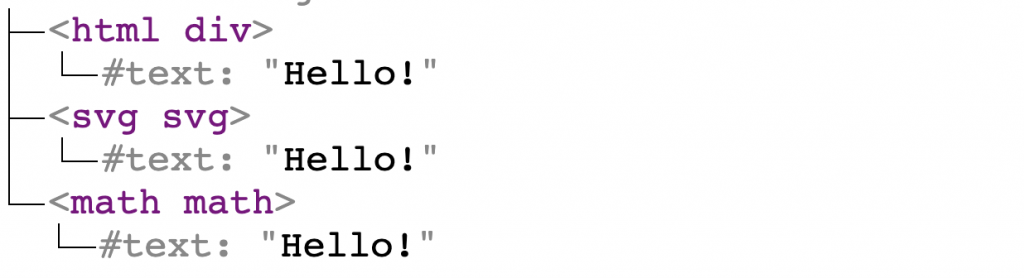
From now on, all DOM trees will have elements prepended with a namespace. So in this example, we can see that div is in HTML namespace, svg is in SVG namespace and math is in MathML namespace.
The namespace of an element affects its parsing as well as its special behavior if it has any. For instance <canvas> can only be used to draw graphics and animations if it is in HTML namespace. It is just a “normal” element in foreign content.
Furthermore, certain elements in HTML are parsed specially. For instance, <style> element can only have text nodes as children after parsing. The same, however, is not true for foreign content. Consider the following example:
|
1 2 |
<div><style><a>am I a new tag?</a></style></div> <math><style><a>am I a new tag?</a></style></math> |
which is parsed into:

Note how #text is the only child in <html style> but <math style> has a child element.
The difference in parsing of <style> between HTML and foreign content is the most typical way to exploit bugs in sanitizers. Consider the following markup:
|
1 |
<math><style><a style="</style><img src onerror=alert(1)>"> |
which is parsed into:

Note that this markup is harmless as the snippet that looks like XSS payload is in the style attribute. However, if we found any way to force the parser to parse style in HTML namespace, instead of MathML, then the DOM tree is different in a quite significant way:

Because <html style> can only have text, then </style> closes it and <img> is created in the DOM tree.
Switching namespaces
Let’s now talk about the possible ways to switch namespaces in HTML. By default, most elements just inherit namespace of their parent. But there are certain elements that makes the child switch namespace of their parent.
You already know two of them: if we are in HTML namespace, then <svg> and <math> switch namespace. Now the question is? Is it possible to have an HTML element with foreign content (that is: SVG or MathML namespace)? The answer is: yes.
Probably the most known example is <foreignObject> SVG element whose purpose is precisely to allow to embed non-SVG elements. So if we have the following markup:
|
1 |
<svg><foreignobject><div>Hello! |
Then it is parsed into the following DOM tree:

Now <div> has HTML namespace even though its parent has SVG namespace.
In HTML specification, <foreignObject> is one of a few HTML integration points – a list of elements that make their children switch namespace. These elements are:
<math annotation-xml>but only if it has attributeencodingwith value eithertext/htmlorapplication/xhtml+xml<svg foreignObject><svg desc><svg title>
But these are not all! There is also another list of elements, called MathML text integration points that also allow to switch namespaces. These are:
<math mi><math mo><math mn><math ms><math mtext>
But here’s a catch: the children of these elements will switch namespace with two exceptions: <mglyph> and <malingmark> are still going to be in MathML namespace. Let’s check that with an example:
|
1 2 3 4 5 6 |
<math> <mtext> <mglyph></mglyph> <div></div> </mtext> </math> |
parsed into:

So div is in HTML namespace and mglyph is MathML namespace even though both of them are direct children of MathML text integration point. Also worth noting is that mglyph is going to be in MathML namespace only if it is a direct child of MathML text integration point. So the following markup:
|
1 2 3 4 5 6 7 |
<math> <mtext> <div> <mglyph></mglyph> </div> </mtext> </math> |
would yield <mglyph> in HTML namespace:

The last important thing is that certain elements end the foreign content right away; that is, they cannot be direct children of foreign content elements unless they are MathML text integration points or HTML integration points.
One example is <s>. Let’s try the following markup:
|
1 2 3 |
<svg> <s></s> </svg> |
Even though we may assume that <s> is going to be a child of <svg>, it is not true:

In HTML specification there’s a list of HTML-specific elements that cannot be a direct children of foreign content element, which includes s, p, span, div and others.
DOMPurify bypasses root cause
So now we know all the basic theory of foreign content. Now I’m just going to recap shortly these two DOMPurify bypasses I mentioned in the beginning of the post.
The first issue was in the parsing of end tag </p> in Chromium and Safari. The following snippet:
|
1 |
<svg></p> |
was parsed into the following DOM tree:

As I mentioned in the previous section, p is one of the elements that cannot be a direct children of element in foreign content. So when this snippet is serialized to:
|
1 |
<svg><p></p></svg> |
And then parsed again, a different DOM tree is created:
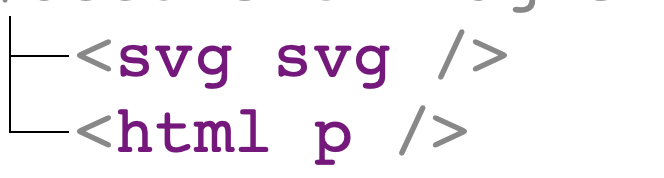
So we clearly have a mutation here; that is, when we serialize a DOM tree and parse it again, we get a DOM tree that is not equal to the original one. This was pretty bad as far as DOMPurify is concerned because it couldn’t make the right decision whether a given markup is safe or not. Consider the following snippet:
|
1 |
<svg></p><style><a title="</style><img src onerror=alert(1)>"> |
It is parsed into:

However, after serializing and reparsing, <html p> “escapes” <svg svg> and all subsequent tags are also parsed in HTML namespace, leading to a different DOM tree:

Please note that the root cause of this issue was in the fact that <html p> element should not appear as a direct child of svg in the first place. If that didn’t happen, then the whole exploit wouldn’t work.
Let’s now have a look at another example of DOMPurify bypass. I’m going to use payload that was posted by Sapra instead of my own, because I believe that it is easier to understand.
Before going to the payload itself, let’s focus of one oddity of parsing of <table>. Consider the following snippet:
|
1 2 3 |
<table> I AM INSIDE TABLE </table> |
It is parsed into a DOM tree that might be quite surprising:

So even though in the markup the text I AM INSIDE TABLE is clearly inside table, after parsing <html table> is actually empty and text occurs in front of the element. The exact reason for that is not that easy to explain and is not really important for our case, but the simplification is that if you don’t use tags that are specific for <table> (like <tr>, <td> etc.) inside the table, then they will be moved in front of the table.
So let’s now have a look at the payload:
|
1 |
<math><mtext><table><mglyph><style><s><img src onerror=alert(1)> |
And the DOM tree:

So we have the MathML text integration point <mtext>. And even though <mglyph> is its direct child, it is still in HTML namespace. The reason for that is that in the original markup, <table> was before <mglyph>, so <table> made the parser switch namespace, and then <mglyph> was parsed in the same namespace. Also, <style> is in HTML namespace as well.
Then the DOM tree is serialized to:
|
1 |
<math><mtext><mglyph><style><s><img src onerror=alert(1)></style></mglyph><table></table></mtext></math> |
Note <mglyph> is now the first child of <mtext> so after a subsequent parsing it will be in MathML namespace. <style> will also be in MathML namespace, while <s> will close the foreign content, making the <img> tag appear in HTML namespace:

Now let’s have a look at these two bypasses, and try to find a common root cause.
In the first case, the root cause was the <html p> being a direct child of <svg svg> which doesn’t happen in “ordinary” markup. In the second case, the root cause was in the fact that <mglyph> switched namespace after reparsing. Also, while <mglyph> is in the allow-list of DOMPurify, it is meant to be in MathML namespace so it shouldn’t be allowed in HTML namespace at all.
DOMPurify fix
So I came up with an idea that verification of namespace of all elements could get rid of these bypasses as well as other bypasses that were discovered in the meantime, by @PewGrand and @bananabr.
Here’s the general idea:
- We need a list of all elements that are defined in SVG specification and MathML specification; only these elements should be allowed in their respective namespaces. This will kill exploits that abuse elements in unexpected namespaces, for instance
<svg p>. - We also disallow elements in HTML namespace that all specific for foreign content. So
<mglyph>should never be in HTML namespace. - We carefully check namespaces switches with the following rules:
- The only way to switch from HTML to SVG or MathML is via
<svg>or<math>respectively. - The only way to switch from SVG to HTML is via HTML integration points.
- The only way to switch from SVG to MathML is via
<math>and HTML integration points. - The only way to switch from MathML to SVG is via
<svg>and either<annotation-xml>or MathML text integration points. - The only way to switch from MathML to HTML is via MathML text integration points.
- If we notice a switch that doesn’t match the rules above, then element is deleted.
- The only way to switch from HTML to SVG or MathML is via
If you wish to take a closer look at the changes made in DOMPurify, have a look at this point: https://github.com/cure53/DOMPurify/blob/main/src/purify.js#L502
I really hope that the new defense mechanism is going to be successful and will basically kill exploits that comes from elements being in unexpected namespaces.
Summary
In this blog post I explained changes I made to DOMPurify to improve its protection against mutation XSS via namespace switching.
In the next post, I’ll explain a second change in the same pull request, which was meant to prevent attacks coming from differences between document parsing and fragment parsing.