On Jun 16, 2020 a security advisory for Ruby Sanitize library was released about an issue that could lead to complete bypass of the library in its RELAXED config. I have found this bug during a penetration test conducted by Securitum, and in this post I’ll explain how I came up with the idea of the bypass and show how it worked.
Sanitizer basics
This section contains basic information about the idea of HTML sanitizers and how they work. If you’re familiar with this topic, you can safely skip to the next section.
Sanitize is a Ruby library that acts as an HTML sanitizer. Its goal is to take an untrusted HTML markup, remove potentially unsafe elements and attributes, and produce new, “safe” HTML. Actually, sanitize is allowlist-based, which means that it removes all elements and attributes that are not contained in a list. You can define your own allow-list (for instance, you may want to allow only <b> and <i> tags), but there are a few predefined ones. In this post I’ll specifically talk about config named RELAXED with the following list of allowed elements:
|
1 2 3 4 5 |
a abbr address article aside bdi bdo blockquote body br caption cite code col colgroup data dd del dfn div dl dt figcaption figure footer h1 h2 h3 h4 h5 h6 head header hgroup hr html img ins kbd li main mark nav ol p pre q rp rt ruby s samp section small span strike style sub summary sup sup table tbody td tfoot th thead time title tr ul var wbr |
Usually the work of a sanitizer can be summarized in three steps:
- Parse HTML into the DOM tree.
- Remove not allowed elements and attributes from the DOM tree.
- Serialize the new DOM tree into HTML markup.
As an example, let’s see how a sanitizer would process the following markup:
|
1 |
ABC<script>alert(1)</script><img src=1 onerror=alert(2)> |
It is parsed into the following DOM tree:

The script tag and onerror attribute are not in the allowlist, and would get deleted. This would result in the following DOM tree:

And after serialization:
|
1 |
ABC<img src="1"> |
To summarize, thanks to sanitization the initial unsafe HTML was rewritten to a safe form.
Parsing and serialization of STYLE
The allowlist of sanitize library contains the style element; this looked promising because it exhibits some specific behavior. First of all, the HTML parser doesn’t decode HTML entities within the <style>. Consider the following HTML:
|
1 2 |
<div>I <3 XSS</div> <style>I <3 XSS</style> |
It gets parsed to the following DOM tree:

Note that < entity is decoded to < in <div> but it is not decoded at all within <style>.
Similarly, serialization of text content of most elements yields escaped text (that is, &"<> are substituted with &"<> respectively) but for some elements, <style> included, the text is written literally.
Consider the following DOM tree:

It is serialized to:
|
1 2 |
<div>I <3 XSS</div> <style>I <3 XSS</style> |
Note that < was escaped to < in <div> but not in <style>.
The fact that text is not escaped in <style> has an important effect: if the text content of <style> is equal to </style><img src onerror=alert(1)>, as in the following DOM tree:

Then it is serialized to:
|
1 |
<style></style><img src onerror=alert(1)> |
And when the serialized form is parsed again, an XSS is introduced. This risk is directly mentioned in the HTML specification:

The question that remains is: how to put text </style> within STYLE element?
The answer is…
Foreign content
The HTML specification has a pandora box of security issues called foreign content. In a nutshell, foreign content is introduced when <svg> or <math> tag is opened in the markup; and the parsing changes drastically. The two characteristics of <style> I mentioned in the previous section are no longer true. If <style> is descendant of <svg> or <math>, then HTML entities are decoded on parsing as well as the text is HTML-encoded on serialization.
To show it a simple example: we start with the following markup:
|
1 |
<svg><style>I <3 XSS |
It is parsed to the following DOM tree:

Note that < was decoded to < which was not the case when <style> was outside of <svg>. The DOM tree is serialized back to:
|
1 |
<svg><style>I <3 XSS</style></svg> |
Again, while < was not encoded to < in <style>, the rule no longer applies to <style> being a child of <svg>.
Sanitize bypass
Going back to the point, let’s see how the Sanitize library could be bypassed. The RELAXED config allowed <style> element but not <svg> or <math> elements. Sanitize use Google Gumbo parser, which is an HTML5-compliant parser, so it is fully aware of all specifics I mentioned above.
Sanitize sanitized CSS rules too, but the easy trick to put arbitrary content in <style> was just to do it within a comment.
So the bypass was as follows:
|
1 |
<svg><style>/*</style><img src onerror=alert(1)*/ |
Let’s go step-by-step. First, Sanitize parses the markup to the following DOM tree:
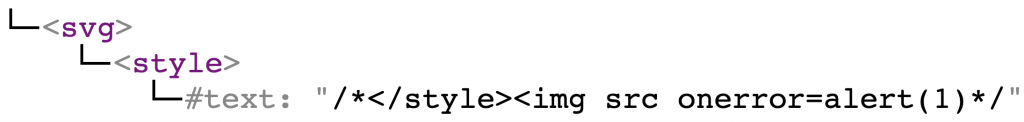
<svg> is not in the allow-list and gets deleted. However, the content of <svg> was left behind. So at this point the DOM tree is as follows:
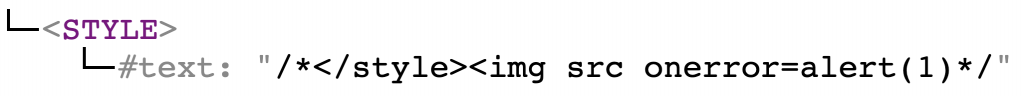
There is nothing more to sanitize, hence the code is serialized to:
|
1 |
<style>/*</style><img src onerror=alert(1)>*/ |
And this introduces the XSS.
Summary
Ruby Sanitize library had a security issue that made it possible to bypass it completely should the website use the RELAXED config. After my report, the default behavior of removing <svg> and <math> elements was altered so that their content is also removed.
I’d like to thank Ryan Grove (the maintainer of the library) for his quick reaction for my report; the fix was released 24 hours after my initial report. Great work!