Introduction
HTTP headers, URLs, URIs, requests, responses, percentage encodings, HTML forms, parameters sent by the HTTP protocol, various HTTP server implementations resulting in security problems – these are just a few elements that I will address in this text. The beginner readers will learn the necessary basics to further explore the subject of web applications security, the more advanced will have the opportunity to revise their knowledge.
In this article, I will focus on the basics of the first version of the HTTP protocol (the second version is available also: https://tools.ietf.org/html/rfc7540. While writing these words, the third one is in progress: https://quicwg.org/base-drafts/ draft-ietf-quic-http.html). The information I present is directed primarily at people focusing on the security of web applications. This is not a compendium regarding HTTP. If you are interested in purely encyclopedic knowledge, I refer to the RFC document, describing HTTP in version 1.1: https://tools.ietf.org/html/rfc7230. Let me add that I will not mention the elements related to HTTPS.
Formal specifications, habits and reality are three different, often distant, matters. Many security problems happen due to the unobvious differences between these three areas. Examples? Let’s get started with the HTTP protocol specifics.
Basic HTTP communication
In most cases, we will meet with HTTP communication, which uses the TCP protocol (although sometimes UDP protocol can be used, see: https://en.wikipedia.org/wiki/Simple_Service_Discovery_Protocol).
HTTP communication is carried out by sending a request to the server, which then generates a response. An example can be seen in the figure below:
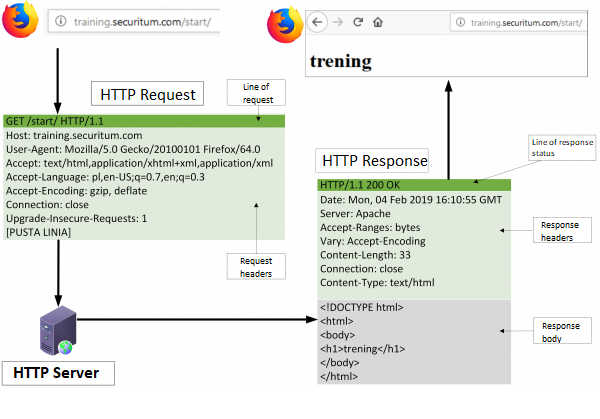
Let’s start the analysis of our communication with an HTTP request (to simplify the example, I have removed unnecessary headers from it):
|
1 2 3 |
GET /start/ HTTP/1.1 Host: training.securitum.com [empty-line] |
The first line of the request contains:
- The method/verb (in our case, it is: GET)
- URL (in our case, it’s: /start/)
- The version of the protocol (in our case, it is: HTTP/1.1)
I would like to highlight the spaces separating the above elements. There must be exactly two of them according to the structure:
METHOD[spacebar]URL[spacebar]HTTP_VERSION
The second line of the above request contains a header. The name of the header: Host, and its value: training.securitum.com
In a more low-level form, this communication looks like this:
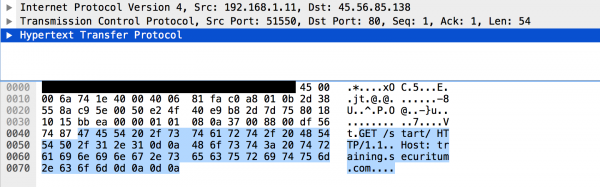
At this point, it is worth paying attention to the last four (hexadecimal) characters: 0d0a0d0a. String: 0d0a is the line separator in the HTTP protocol. Often this string is marked as CRLF. By the way, I would like to add that in Polish, someone proposed a quite poetic translation of the slightly dry CRLF:
I would try to go more with the onomatopoeia: KSHSHDING! (Understandable to the older people who used a typewriter).
So, we have one KSHSHDING! after the Host header and the second after all the headers (the HTTP protocol requires this).
Sometimes, we can read that there is an ’empty line’ after the headers in the HTTP request. What is it? The sequence 0d0a0d0a mentioned above, or otherwise the other two consecutive CRLFs.
Why am I focusing on such a minor detail? Because in the heat of battle, some will send an HTTP request with only one end-of-line character after the headers, which is not correct and usually ends with an HTTP server waiting just for the CRLF character (it looks as if the server did not respond…).
It is worth to do a simple exercise here. Using the free version of the Burp Suite tool (see https://portswigger.net/burp/communitydownload and the introductory video here: https://sekurak.pl/movies/screencast_burp_starter_sub04-20171125.mp4), send an HTTP request, ending only with one line break. After establishing the communication, we do not get a response (or after some time, we get an error from the HTTP server: Request Timeout):
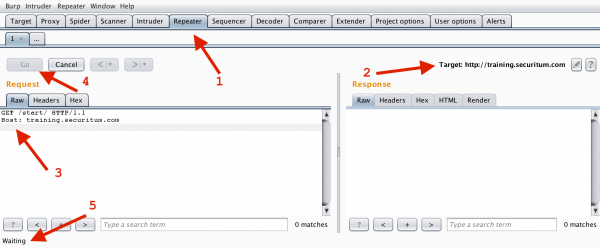
Figure 3. Only one CRLF after the last header results in awaiting (point 5.)
In the case of two end-of-line characters, everything will go smoothly:
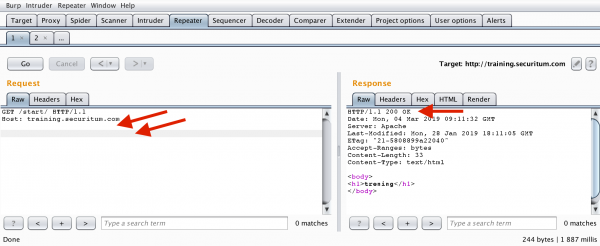
Inquisitive readers will probably notice that the request shown in Figure 4 shows two empty lines (not one as I wrote earlier). So then, how is it supposed to look like? I will remind you once again, the HTTP specification says about the required two 0d0a strings (CRLF and familiar KSHSHDING) after the last header. Some people interpret this as one empty line, but in some cases (Burp Suite), we see two. Both interpretations are correct, and it is important only for real communication to look like in Figure 2 (I mean the very end of the request).
After sending the request, the server responds to us in the following way:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
HTTP/1.1 200 OK Date: Mon, 28 Jan 2019 18:15:03 GMT Server: Apache Last-Modified: Mon, 28 Jan 2019 18:11:05 GMT ETag: “2d2e0-21-5808899aa4c5d” Accept-Ranges: bytes Content-Length: 33 Vary: Accept-Encoding Content-Type: text/html <body> <h1>training</h1> </body> |
We can see the following elements here:
- Response status line: HTTP/1.1 200 OK
- Subsequent response headers, e.g.: Server: Apache
- Empty line
- Body of the answer:
<body>
<h1>training</h1>
</body>
Let’s get back to the HTTP request described earlier and discuss its elements in more detail.
HTTP methods
This time, we will try to use other methods than GET. The HTTP specification defines several of them (see https://tools.ietf.org/html/rfc2616#section-5.1.1). You can actually find several dozens of them. For starters, let’s try to send a request using the HEAD method:
|
1 2 3 |
HEAD / HTTP/1.1 Host: training.securitum.com [empty-line] |
We will get an analogous answer as before, but without the body of the answer (as you can see, the correct HTTP response does not have to contain it) but with one empty line at the end:
|
1 2 3 4 5 6 7 8 9 10 |
HTTP/1.1 200 OK Date: Mon, 28 Jan 2019 18:37:40 GMT Server: Apache Last-Modified: Mon, 28 Jan 2019 18:11:05 GMT ETag: „2d2e0-21-5808899aa4c5d” Accept-Ranges: bytes Content-Length: 33 Vary: Accept-Encoding Content-Type: text/html [empty-line] |
Note: For simplicity, in the following examples, I will omit the designation [empty-line].
Where can such a method be useful? For example, when trying to locate some hidden files and directories by brute force:
|
1 2 |
HEAD /test HTTP/1.1 Host: training.securitum.com |
In response, we get information without the body of the response. Thanks to this, we accelerate a single test (the server must send fewer bytes in response):
|
1 2 3 4 5 |
HTTP/1.1 404 Not Found Date: Mon, 28 Jan 2019 18:39:18 GMT Server: Apache Vary: Accept-Encoding Content-Type: text/html; charset=iso-8859-1 |
It is worth noting that the resource / exists (we received the response code 200), and the resource /test does not (we received the error code 404). Of course, this is not always the case; for example, the server can return the 200 code and let us know about the problem in the body of the answer.
What are other methods available? For example, OPTIONS, indicating the methods supported by the server (it is worth remembering that the information returned in response does not always have to be true…):
|
1 2 |
OPTIONS / HTTP/1.1 Host: training.securitum.com |
|
1 2 3 4 5 6 7 |
HTTP/1.1 200 OK Date: Mon, 28 Jan 2019 18:41:41 GMT Server: Apache Allow: GET,HEAD,POST,OPTIONS Vary: Accept-Encoding Content-Length: 0 Content-Type: text/html |
In the context of our considerations, the PUT method is very dangerous (it is often disabled by default), which allows creating files on the HTTP server:
|
1 2 3 4 |
PUT /test2.php HTTP/1.1 Host: training.securitum.com Content-Length: 19 <?php phpinfo(); ?> |
|
1 2 |
HTTP/1.1 201 Created Location: /test2.php |
As we can see, in the body of the request, we give the contents of the file, and in the first line, its name. If the method is supported, we now can send a request to the newly created test2.php file, and, basically, we can execute arbitrary code on the server!
By the way, it is also worth adding that the methods do not always have to be used in capital letters.
Maybe the PUT method is forbidden, but the pUt is not?
|
1 2 3 4 |
pUt /test2.php HTTP/1.1 Host: training.securitum.com Content-Length: 19 <?php phpinfo(); ?> |
At this point, it should be clarified that after the body of the query, we no longer have the line break (CRLF). It may exist there, but it will be treated as the body’s content.
URL or URI?
Allow me to start with pointing out that in the context of HTTP, a very popular term is URL (Uniform Resource Locator). Historically (see: https://tools.ietf.org/html/rfc1738), this was simply an address that can be used in an HTML hyperlink, e.g.:
|
1 |
http://training.securitum.com/request.php?param=value |
Often, the “URL” is simply a string that we enter in the address bar (sometimes explicitly referred to as the URL bar) of the browser.
It looks simple and intuitive, right? The problem is that in many specifications (also regarding the HTTP protocol, see: https://tools.ietf.org/html/rfc7230), we will not find the term URL. Often, we will only talk about URI (Uniform Resource Identifier).
Formally, URLs are a subset of the URI (Uniform Resource Locator), see: https://tools.ietf.org/html/rfc3986. Should we erase the “heresy of URLs” from memory and use the term URI? Definitely not. Many people use these terms interchangeably (without losing the precision of reasoning). There was even a corresponding RFC document, explaining the whole confusion: https://tools.ietf.org/html/rfc3305.
Nonetheless, we will use both URL and URI terms alternatively for our needs. It is often that we encounter these types of URLs:
|
1 |
http://trainig.securitum.com/katalog/test.php?param=value#fragment |
But we can extend it (notice a different port and an optional part about the user and password):
|
1 |
http://user:hasło@trainig.securitum.com:8042/katalog/test.php?param=value#fragment |
Note the fragment, this is a popular reference to the anchor in HTML, and entering such a URL in the browser does not send the # character to the server and what is after it.
Sometimes, the @ sign is also problematic, because of the question: how to interpret the following URL?
|
1 |
http://sekurak.pl@trainig.securitum.com@securitum.com/ |
Is this correct at all? To what domain does it lead?
Interestingly, using the URL with the user and password directly in the HTTP request is not valid:
|
1 2 |
GET http://login:password@training.securitum.com/ HTTP/1.1 Host: training.securitum.com |
So, shall we always get the following error in response?
|
1 |
HTTP/1.1 400 Bad Request |
Often yes, although I suspect there may be HTTP servers that will easily allow this type of URI.
URLs can also have a relative form, e.g.:
|
1 |
/catalog/test.php?param=value |
And this is what we see most often in HTTP requests.
Equipped with the theoretical foundations regarding the concept of URL (or URI), let’s see a simple example of a request:
|
1 2 |
GET /test HTTP/1.1 Host: training.securitum.com |
In this case, the URL is relative: / test, however, we can also use the absolute version here:
|
1 2 |
GET http://training.securitum.com/test HTTP/1.1 Host: trening2.securitum.com |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
HTTP/1.1 200 OK Date: Mon, 28 Jan 2019 19:29:28 GMT Server: Apache Last-Modified: Mon, 28 Jan 2019 18:11:05 GMT ETag: „2d2e0-21-5808899aa4c5d” Accept-Ranges: bytes Content-Length: 33 Vary: Accept-Encoding Content-Type: text/html <body> <h1>training</h1> </body> |
It is rare to find this type of URL in real HTTP requests, but it is correct and might have some interesting security implications.
In the above example, the value of the Host header will be most often ignored by the server. This type of behaviour can sometimes be used to locate vulnerabilities. An example can be found in the following work in the Host overriding section:
https://portswigger.net/blog/cracking-the-lens-targeting-https-hidden-attack-surface
Some servers effectively whitelist the host header but forget that the request line can also specify a host that takes precedence over the host header.
|
1 2 3 |
GET http://internal-website.mil/ HTTP/1.1 Host: xxxxxxx.mil Connection: close |
Apparently, on the server-side, it is checked whether the Host header accepts one of the allowed values (i.e., domains that can be referenced), but someone has forgotten that the URL from the first line takes precedence!
It is worth to highlight one more element here. The URL is often normalised by the browser, for example, entering the following address in the browser’s address bar: training.securitum.com/test/../ sends the standard version to the server, i.e.:
|
1 2 |
GET / HTTP/1.1 Host: training.securitum.com |
Therefore, in our applications, it is better to use a tool other than a browser to send HTTP requests, e.g. Burp Suite or OWASP ZAP.
HTTP headers
So far, we have mainly focused on the first line of the request. Let’s now look at the Host header, the only HTTP protocol required in version 1.1. Is the name given here simply represent a domain address that we enter in the browser? Very often, the answer is yes, but let’s check how the browser connects to the HTTP server:
- In the browser address bar, we enter: training.securitum.com
- A query is made to the DNS server, giving us the IP address: 45.56.85.138
- The browser connects to this address using the HTTP protocol (on port 80) and sends the previously mentioned HTTP request with the header Host: training.securitum.com
Can we use a different name in the value of the Host header? As much as possible, even one that we do not have in DNS:
|
1 2 |
ptest$ host training2.securitum.com Host trening2.securitum.com not found: 3(NXDOMAIN) |
|
1 2 |
GET / HTTP/1.1 Host: training2.securitum.com |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
HTTP/1.1 200 OK Date: Mon, 28 Jan 2019 19:02:38 GMT Server: Apache Last-Modified: Mon, 28 Jan 2019 19:02:04 GMT ETag: „2d2e1-29-580894ff98fe3” Accept-Ranges: bytes Content-Length: 41 Vary: Accept-Encoding Content-Type: text/html <body> <h1>looks like an old clunker</h1> </body> |
Note that this method can be used to locate hidden virtual domains on a given server, and the fact that they are not in DNS does not bother you at all. A specific example of this type of activity can be seen here: https://sites.google.com/site/testsitehacking/10k-host-header
Author of this find manipulated the Host header and obtained access to the yaqs.googleplex.com domain where Google’s confidential information was kept. For reporting the vulnerability, the researcher received $10,000 as part of the official bug bounty program.
Are there other HTTP headers? Of course. It is worth mentioning that the headers transmitted in the request are one thing, and the headers sent in response are something else. Some headers may be named the same, e.g. Content-Type. In such cases, it is worth adding whether we are asking for a request or response header.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
HTTP/1.1 200 OK Date: Mon, 28 Jan 2019 19:02:38 GMT Server: Apache Last-Modified: Mon, 28 Jan 2019 19:02:04 GMT ETag: „2d2e1-29-580894ff98fe3” Accept-Ranges: bytes Content-Length: 41 Vary: Accept-Encoding Content-Type: text/html <body> <h1>looks like an old clunker</h1> </body> |
A few headlines worth mentioning:
- Cookie (request header) – sends a cookie to the server
- Set-Cookie (response header) – sets the cookie to the customer
- Server (response header) – cheating timestamp/version of the HTTP server being used
- X-Forwarded-For (request header) – extremely interesting header with potential for security violation: https://sekurak.pl/naglowek-x-forwarded-for-problemy-bezpieczenstwa/
- Strict-Transport-Security (response header) – one of the headers that may increase the security of our application (see: https://sekurak.pl/jak-w-prosty-sposob-zwiekszyc-bezpieczenstwo-aplikacji-webowej/)
- Accept (request header) – informs which data formats the client accepts. It is worth pointing out here at the same time that quite unobvious vulnerability in Ruby on Rails (CVE-2019-5418) enabled through the appropriate crafting of the Accept header reads files from the server, see: https://chybeta.github.io/2019/03/16 /-Analysis for% E3% 80% 90cv-2019-5418% E3% 80% 91File-Content-Disclosure-on-Rails/).
- Location (response header) – performs client redirection to a different address. An example of a response with the Location header is given below:
|
1 2 3 4 5 6 7 |
HTTP/1.1 302 Found Date: Tue, 29 Jan 2019 17:16:35 GMT Server: Apache Location: http://sekurak.pl/ Vary: Accept-Encoding Content-Length: 0 Content-Type: text/html |
Finally, it’s worth mentioning that headline names can be written with any combination of uppercase and lowercase letters, e.g. hOSt.
More information about the headings can be found here:
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers
- https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
Values passed to the application by HTTP protocol
This is one of the most critical, underlying themes in the context of security. An overwhelming number of vulnerabilities in web applications can be used by appropriately (malicious) manipulating the values passed to the application.
So, where are the parameters for HTTP requests? A slightly evasive answer is everywhere. Starting from the request line, through the headers, to the body.
Let’s look at some popular places where we can find parameters.
URL
The parameters passed in the URL will most often be seen in GET type queries. Many of us have certainly seen this type of construction placed in the address bar of the web browser:

Browser, based on this address, performs the following HTTP request (manually removed from it less important headers):
|
1 2 |
GET /start/request.php?param1=value1¶m2=value2 HTTP/1.1 Host: training.securitum.com |
|
1 2 3 4 5 6 7 |
HTTP/1.1 200 OK Date: Mon, 04 Mar 2019 09:15:30 GMT Server: Apache Content-Length: 39 Content-Type: text/html; charset=UTF-8 parameter1: value1 parameter2: value2 |
Remember that this is just a convention. The application may as well use the parameter name as a value (in our case it is parameter1).
What happens when we add an additional parameter not supported by the application? E.g. parameter3? Most often, nothing:
|
1 2 |
GET /start/request.php?param1=value1¶m2=value2¶m3=value3 HTTP/1.1 Host: training.securitum.com |
|
1 2 3 4 5 6 7 |
HTTP/1.1 200 OK Date: Mon, 04 Mar 2019 09:16:28 GMT Server: Apache Content-Length: 39 Content-Type: text/html; charset=UTF-8 parameter1: value1 parameter2: value2 |
Sometimes, however, the application analyses all the parameters sent (e.g. by the GET method), so it is worth checking what will happen if we pass this type of additional value.
Inquisitive readers may ask: is it possible to send in a parameter value, e.g. the ‘&’ sign (as seen above, it has a special meaning) or ‘#’ (previously mentioned that the # sign typed in the browser bar is not sent to the server)? Of course, you can do this using percentage encoding (see: https://tools.ietf.org/html/rfc3986) often referred to as URL encoding. It works in a simple way: the ASCII code of the character & is hexadecimal 26. In percentage encoding, % 26.
If you want to use spaces in the URL, you must encode it as % 20 (or as +). For this reason, the use of the plus sign must also be coded (as % 2b). Otherwise, it would mean a coded space.
Can we encode other characters (e.g. in the parameter name)? Of course:
|
1 2 |
GET /request%2ephp?param1=a%2bb&p%61rametr2=a%26+b%20c HTTP/1.1 Host: training.securitum.com |
|
1 2 3 4 5 6 7 8 |
HTTP/1.1 200 OK Date: Tue, 29 Jan 2019 19:47:52 GMT Server: Apache Vary: Accept-Encoding Content-Length: 32 Content-Type: text/html parameter1: a+b parameter2: a& b c |
I will add that, sometimes, the percentage coding is confused with the entity coding, often used in HTML, e.g.: & lt; & Amp. It’s a completely different coding and the latter cannot be used in the URL.
Lastly, it is worth mentioning that it is recommended that the GET method should not send sensitive data, e.g. passwords or session identifiers. Why? These parameters can be seen directly in the browser’s URL bar. By default, they are logged by HTTP servers or visible on the results of search engines.
POST: application/x-www-form-urlencoded
The second common way to send parameters is to send them to the body of the request using the POST method. Often, this is how data from HTML forms are sent. Example:
|
1 2 3 4 5 |
<form action=”/request.php” method=”POST”> Enter the parameter 1: <input type=”text” name=”parameter1″><br> Enter the parameter 2: <input type=”text” name=”parameter1″><br> <input type=”submit”> </form> |
In the <form> tag, we can also specify the enctype parameter, which indicates the browser how it should send from the form in the request:
|
1 |
<form action=”/request.php” method=”POST” enctype=”application/x-www-form-urlencoded”> |
The value of application /x-www-form-urlencoded is the default (so if we want to use it, we can completely omit the enctype parameter), other possibilities are multipart/form-data (more on this later in the text) and text/plain.
At this point, I must suggest implementing a simple exercise that changes the GET method to POST. In the Burp Suite tool (Repeater module), enter the previously described request, then right-click and select the Change Request Method option:
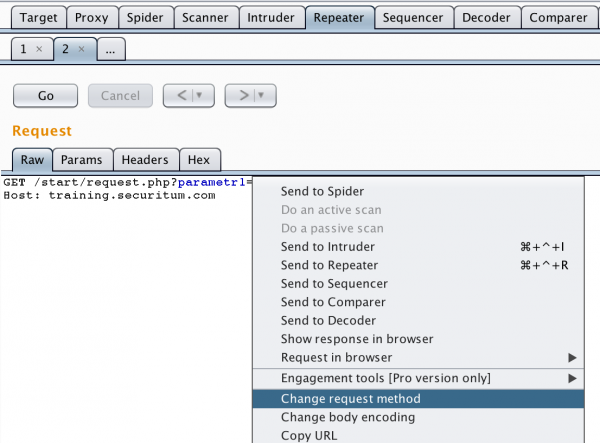
Figure 6. Changing the type of HTTP request
The result of this operation is as following (it is worth noting that the request does not end with a CRLF string, although it may theoretically, then the line break will be part of the parameter value of parameter2):
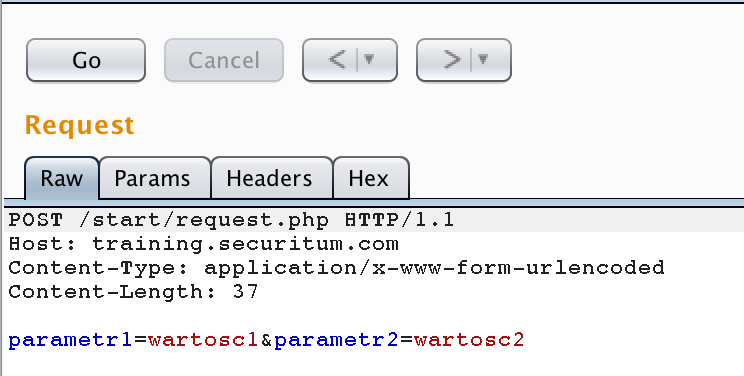
Will the GET method changed to POST always work (or vice versa)? Not necessarily, although it is possible quite often. Sometimes, attackers who gain unauthorised access to the application will want to pass parameters in this way. Why? HTTP servers do not log parameters sent via POST by default (as opposed to parameters passed in the URL).
Getting back to the details of our new request, note that apart from the method change, two additional headers appeared:
|
1 2 |
Content-Type: application/x-www-form-urlencoded Content-Length: 43 |
However, the parameters themselves were in the body (one empty line). Note: we do not have CRLF characters at the end of the request. Technically speaking, they may be there, but then they will be part of the parameter value2 (then Content-Length will also change, indicating the length of the body).
Can the same parameters be transmitted simultaneously in the request line and the body? Of course:
|
1 2 3 4 5 |
POST /start/request.php?parameter1=value1¶meter2=value2 HTTP/1.1 Host: training.securitum.com Content-Type: application/x-www-form-urlencoded Content-Length: 37 parameter1=value1&value2=value2 |
Sometimes, this leads to the creation of interesting vulnerabilities, see, for example, the vulnerability in the WordPress API that allows anonymous change of any entry: https://blog.sucuri.net/2017/02/content-injection-vulnerability-wordpress-rest-api.html
What if we changed the value of the Content-Length header? Will fewer data be sent? None of the above. A full request will be sent, and only the webserver will process the whole thing:
|
1 2 3 4 |
POST /start/request.php HTTP/1.1 Host: training.securitum.com Content-Type: application/x-www-form-urlencoded Content-Length: 7 |
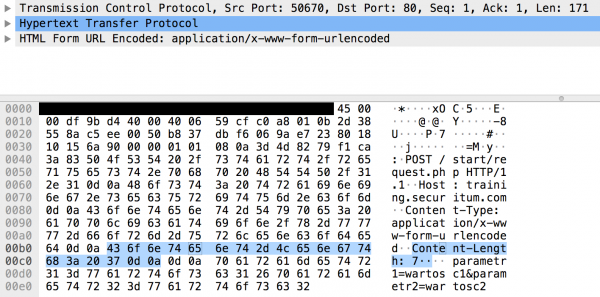
This behaviour can sometimes be used, for example, to bypass application firewalls (see: https://www.slideshare.net/SoroushDalili/waf-bypass-techniques-using-http-standard-and-web-servers-behaviour).
Some say that security people are sometimes a bit nasty. There is probably some truth in it because what else can you call entering a negative value in the Content-Length header? This is as much as possible, and the effects can be varied from Denial of Service errors (see: https://tools.cisco.com/security/center/viewIpsSignature.x?signatureId=4902&signatureSubId=0) to the potential to execute the code on the server (see vulnerability in module mod_proxy Apache HTTP server: http://cve.mitre.org/cgi-bin/cvename.cgi?name=can-2004-0492).
POST: multipart/form-data
Sometimes, parameters sent using the POST method will use just multipart/form-data coding . This type of example is most often found in file uploading forms. Such a request looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
POST /request.php HTTP/2.1 Host: training.securitum.com Content-Type: multipart/form-data; boundary=awnwWejh23kl Content-Length: 323 —awnwWejh23kl content-disposition: form-data; name=”parameter1″ value one –awnwWejh23kl content-disposition: form-data; name=”parameter2″ value two –awnwWejh23kl content-disposition: form-data; name=”our_file”; filename=”file1.txt” Content-Type: text/plain The content of the text file –awnwWejh23kl– |
I would like to highlight the so-called boundary (you can read more about it here: https://tools.ietf.org/html/rfc1521).
Most often, it is random content though it has some limitations (e.g. it has a length limit).
The full delimiter is CRLF (end of line character), two minus signs (-) and the value indicated by the boundary parameter in the header. So in our example, this is -awnwWejh23kl (and earlier enter).
The last stop additionally has two more characters (-) at the end. In our example, this is -awnwWejh23kl-.
In short, our boundary separates the body into multipart. In the considered case, we have three of these parts. Each of them has a header, defining the name of the variable:
|
1 |
content-disposition: form-data; name=”nazwa” |
In turn, after two end-of-line values (CRLF), the variable value is transferred. The value on the other end marks the end of our boundary. In the example below, we see a variable named parameter1 and a value:
|
1 2 3 4 5 6 7 |
value one –awnwWejh23kl content-disposition: form-data; name=”parameter1″ value one –awnwWejh23kl |
Remember that these are just the basics of this type of parameter coding. As an example of using this topic to circumvent WAF (Web Application Firewall) mechanisms, I recommend the article: “WAF Bypass Techniques – Using HTTP Standard and Web Servers’ Behavior” where you can find a lot of interesting bypasses based on smart modifications of HTTP communication.
Finally, let’s consider whether parameters passed in the body of the request can be transmitted using the GET method. The idea seems to be a bit strange, but this type of request is correct, and what’s more, it can sometimes be used to indicate serious vulnerabilities.
Cookies
Popular cookies, sometimes incorrectly referred to as ‘cookie files‘. In the context of our considerations, cookies (which may contain parameters) can be found in the HTTP header of the Cookie.
There may be several different cookies in one header (although the header will always be called Cookie, not Cookies).
Where are the cookies sent from the server? In response, in the Set-Cookie header.
Let’s see an example of both headings. After entering the address in the browser at http://training.securitum.com/start/cookie.php, the server sets two cookies (Set-Cookie response header):
|
1 2 3 4 5 6 7 8 |
GET /start/cookie.php HTTP/1.1 Host: training.securitum.com User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 DNT: 1 Connection: close Upgrade-Insecure-Requests: 1 |
|
1 2 3 4 5 6 7 8 |
HTTP/1.1 200 OK Date: Mon, 04 Mar 2019 09:48:12 GMT Server: Apache Set-Cookie: test-cookie1=test-value2 Set-Cookie: test-cookie2=test-value2 Content-Length: 0 Connection: close Content-Type: text/html; charset=UTF-8 |
The next query from the browser is automatically completed with the Cookie header:
|
1 2 3 4 5 6 7 8 9 10 |
GET /start/cookie.php HTTP/1.1 Host: training.securitum.com User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 DNT: 1 Connection: close Cookie: test-cookie1=test-value2; test-cookie2=test-value2 Upgrade-Insecure-Requests: 1 Cache-Control: max-age=0 |
Summary
After reading the text, you should already have basic knowledge about HTTP communication, which will be useful in real experiments with the security of web applications. Remember that not everyone is clinging to the HTTP specification, and sometimes even trivial deviations from the usual rules can have interesting results (see e.g.: https://www.zdnet.com/article/vulnerability-exposes-location-of-thousands -of-malware-cc-servers/).