The American programmer, Jamie Zawinski, once said, “Some people, when they encounter a problem, think to themselves, ‘I know! I will use regular expressions.’ And now they have two problems.”
In this article, we’ll see how true the words are if the regular expression has been spelled incorrectly, allowing the Denial-of-Service to be launched on the web application.
Basics
This paragraph contains the basics of using regular expressions. Readers familiar with the topic may jump right to the next section.
Regular expressions (regexes) allow programmers to specify a text pattern, and then check whether the string matches the text. In practical applications, these are often used to validate data. For example, if we have an application field in which the user should enter a zip code, we can check its validity by using given expression: ^[0-9]{2}-[0-9]{3}$. Regexes may contain both ordinary characters and special characters. The following is a short cheat sheet of frequently used characters with special meaning:
- “.” (Dot) – matches any character.
- “^” – the beginning of the string.
- “$” – end of the string.
- “*” – regular expression preceding the asterisk can be repeated any number of times (also zero times). For example, the expression “ab *” matches, among others, “abb”, “ab” and “a”.
- “+” – a regular expression preceding a plus can be repeated at least once. So “ab +” will not match the “a” itself anymore.
- “{N}” – regular expression must be repeated exactly n times.
- “[…]” – defines the set of characters that can be matched. They will be either explicitly listed; e.g., “[abz]” or as a range: “[a-z]”. If the first character of the file is “^”, then characters not in the set are matched. For example: “[^a-z]” matches all characters except in lower case letters of the Latin alphabet.
- “|” – equivalent to the OR operator. The regular expression “ab | cd” will match the string “ab” or “cd”.
- “(…)” – grouping of regular expressions.
For example, if we want to match a string starting with “Sekurak“, where \ the string “2016” or “2017” should appear, and then ten digits, we can write it as follows: “^Sekurak (2016|2017)[0-9]{10}” .
Implementations
In the most popular programming languages, such as C# (generally .NET), Python, PHP or Java, the implementation of regular expressions involves building a nondeterministic finite automation (NFA). It works by reading the next tokens from the regular expression and matching them in the checked string. Importantly, by default, regex engines operate in greed mode; i.e., they match as many repetitions of a given character as possible. If the engine determines that a given string does not match the regular expression, then backtracking is used; that is, a return to a place in the regex where the engine could choose a different execution path.
Let’s see it in an example. We have the regular expression “a+.b” and we try to match the string “aab”.

Even in such a relatively simple regular and short string expression, you can see that the first time the regular expression engine adopted the “wrong” path to match it to the string, it had to go back to the previous state to see that the match existed. In other words, the engine checks all possible ways of matching the regular expression before it issues the final judgment or decides if the match exists.
This feature of engines may be abused to perform a Denial-of-Service attack. If the regular expression is written incorrectly (see the example below), the time needed for its analysis can grow exponentially.
“Bad” regular expressions
Let’s take a regular expression: “^(a+)+$”. We have the letter “a” in it, which must appear at least once, entered in a group, which must also occur at least once. If we take a string that matches this expression, such as “aaaaa”, we will get the answer very quickly, because the regex engine will be able to immediately match all letters “a”. But what happens if we deliberately use a string that will not be matched? Let’s see the example of “aab”.

As we can see, an attempt to match a relatively easy regular expression and short sequence of characters required tedious checking of all possibilities by the engine. If we were to create a character string consisting of one letter “a” more, then the engine would need twice as many steps to determine that the regular expression is not matched. In fact, the analysis of this expression consists in an attempt to divide the letters “a” into groups in all possible ways before the result is returned. So for the string “aaaab”, the engine would try the following divisions: “(aaaa)”, “(aaa)(a)”, “(aa)(aa)”, “(aa)(a)(a)”, “(a)(aa)”,”(a)(aa)(a)”,”(a)(a)(aa)”,”(a)(a)(a)(a)”. It is easy to notice that when we have n letters “a” 2n-1 possibilities are checked.
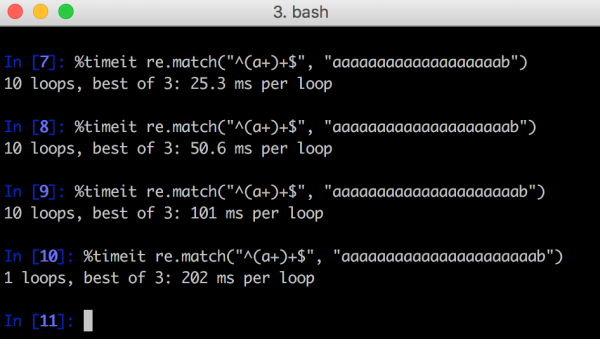
In Figure 1, an example of the Python benchmark is shown in which each addition of one character “a” extends the analysis of the regular expression twice. Of course, adding a dozen or several dozens of characters would make the analysis of the regular expression take a few days, months or years. Running this on the web application could cause the server to be immobilized.
How to defend yourself
Detecting whether a regular expression may be susceptible to a Denial-of-Service problem is not easy. It is particularly difficult to notice the problem in more complex regexes; e.g., matching email or HTML addresses. The warning lamp should always light up if you see a regular expression group in which any repetition operator is used. A repetition operator is also used in the middle of the group itself. Examples:
- “(a+)+”
- “(a+a+)+”
- “(x[a-z]+)*”
If it is possible, beware of this type of regex and try to prescribe it in a different way. One way to check whether a regular expression is susceptible to a problem is to arrange a string of characters that is correct, make minor modifications to it, and then check how they affect the analysis time.
In some applications, it is anticipated that the user may enter the regular expression himself; e.g., in a search engine. In this case, it is recommended to define timeouts for regular expressions in the application. For example, in .NET, timeouts in regex have been supported by the framework for some time. If the programming language that we use does not provide such an option in itself, manual implementation will be necessary.
Summary
Regular expression engines in the most popular programming languages are implemented as a non-terminated finite state machine (NFA). Such an implementation is easy to program but makes the analysis time of some regular expressions grow exponentially depending on the length of the data.
In many programming languages there are no built-in safeguards against such attacks. The most universal method is to implement a timeout for the analysis of a regular expression.